



【要約】
SIGNATEで開催されているコンペ「金融データ活用チャレンジ」でDatabricksのAutoMLが使えるようなので、その使い方をご紹介します。
コンペの本番環境でもAutoMLが使えるようですのでご活用ください。
※ コンペのデータおよび本番環境の公開日(2023年1月20日)前に執筆・公開してます。
※ 本記事公開後、本番環境でもAutoMLが使えるとのこと、事務局からご連絡頂きました。ありがとうございました。
1.What's 金融データ活用チャレンジ
昨年12月23日から3月5日(日)まで、SIGNATEにおいて「金融データ活用チャレンジ」が開催されています。
主催は社団法人ですが、金融機関が開催する国内コンペとしては「MUFG Data Science Champion Ship」に続く国内金融コンペ第二弾という印象です。
コンペの内容は、住宅ローンの延滞者予測となっており、基準月から3か月後に延滞が発生しその後継続した会員を予測し、その精度を競います。
精度の高いモデルを構築することで、延滞する可能性のある会員へのファイナンシャルアドバイスをすることを目的にされています。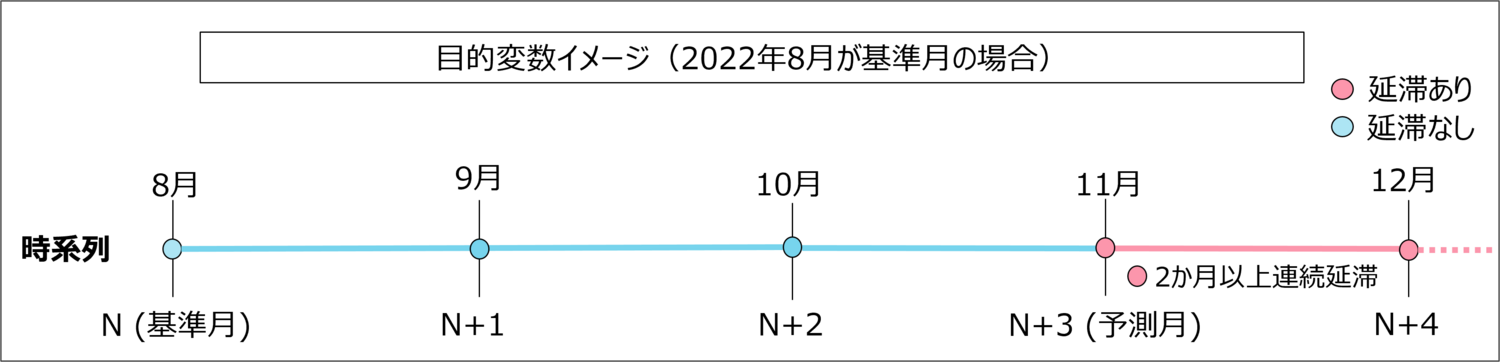 コンテスト概要より引用
コンテスト概要より引用
2.「Databricks」上で行われるコンペ
本ブログを書こうと思ったきっかけです。(Databricksってなに?)
wikiによると「Databricks」とは、
AI/機械学習をはじめとするビッグデータを扱うためのクラウド型の統合データ分析基盤である「レイクハウス・プラットフォーム」を提供しており、データエンジニアリング、データサイエンス/機械学習、データ分析の領域に強みがある。
出典: Wikipedia『データブリックス』
とのことで、要するに、「データを格納・保管するDWHと、そのデータを分析実行するコンピューターリソースをクラウド上で統合的に扱えるようにしたもの」というざっくり理解です。
今回のコンペでは、扱われるデータをローカル環境に保存したり、別のクラウド環境(例えば、GCPやColaboratory)で扱うことができないようです。そのため、データの前処理からモデル構築、予測までをすべてこの「Databricks」上で行うことになります。今回のデータは架空データですが、センシティブなデータを扱う金融機関として今後の活用展開も見据えての開催方式なのかもしれません。
3.「Databricks」AutoML使ってみた
本題です。「Databricks」初めて聞きましたが、コンペに参加すると無料で使えるみたいなので参加して使ってみました。
注目は、Databricks上で利用できるAutoMLです。以下、使い方について記載したいと思います。
なお、コンペに参加していなくても無料のCommunity Editionでも使えるようです。サインアップはこちらの記事がわかりやすかったです。
4.[準備] クラスターの立ち上げ
クラスター名の入力とDatabricks Runtimeのバージョンを選択してクラスターを立ち上げます。
今回は「Runtime: 11.1ML」を選択します。Databricks Runtimeは、自動で環境構築してくれるバージョンみたいなもので、インストールされているライブラリ等はこちらのドキュメントから確認できます。
それぞれ選択できたら、作成ボタンをクリックします。立ち上げまで数分かかります。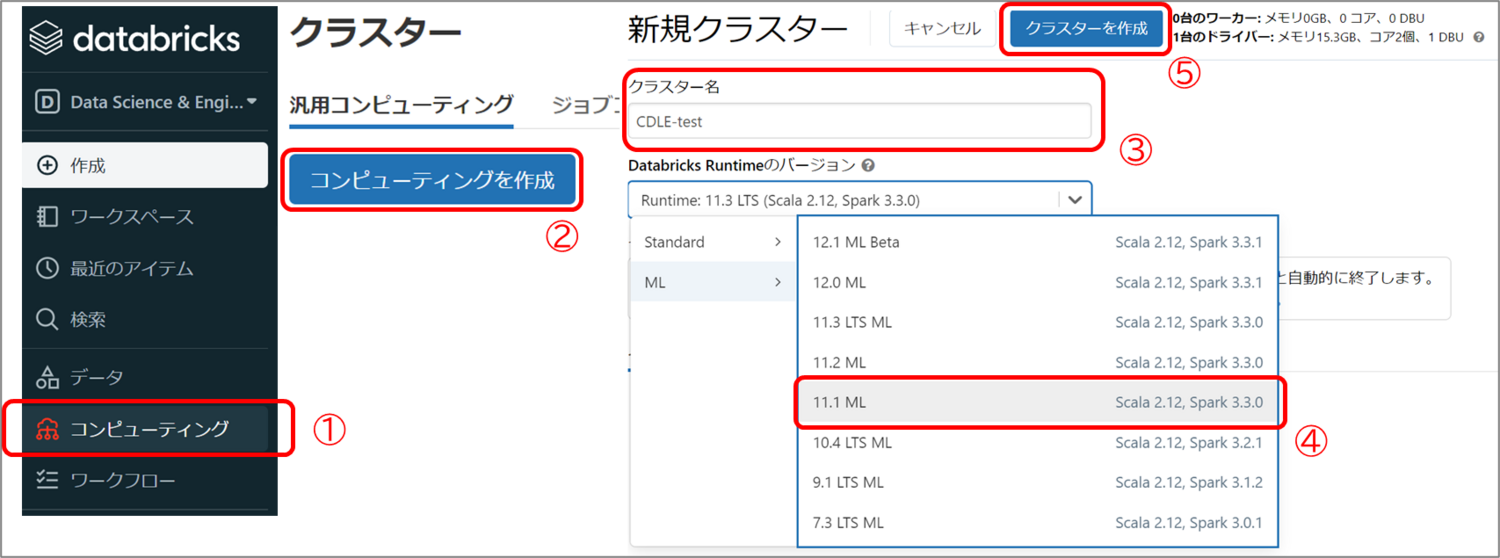 ① Databricksにサインインしたら右Navの「コンピューティング」を選択
① Databricksにサインインしたら右Navの「コンピューティング」を選択
②「コンピューティングを作成」を押下
③ クラスター名入力
④ Databricks Runtime選択
⑤「クラスターを作成」を押下
5.[準備] 公式Notebookのリンクを取得する
自分のDatabricks上に公式Notebookをコピーします。
コピー元となる以下の公式Notebookを開き、右上の「Import Notebook」からリンクを取得します。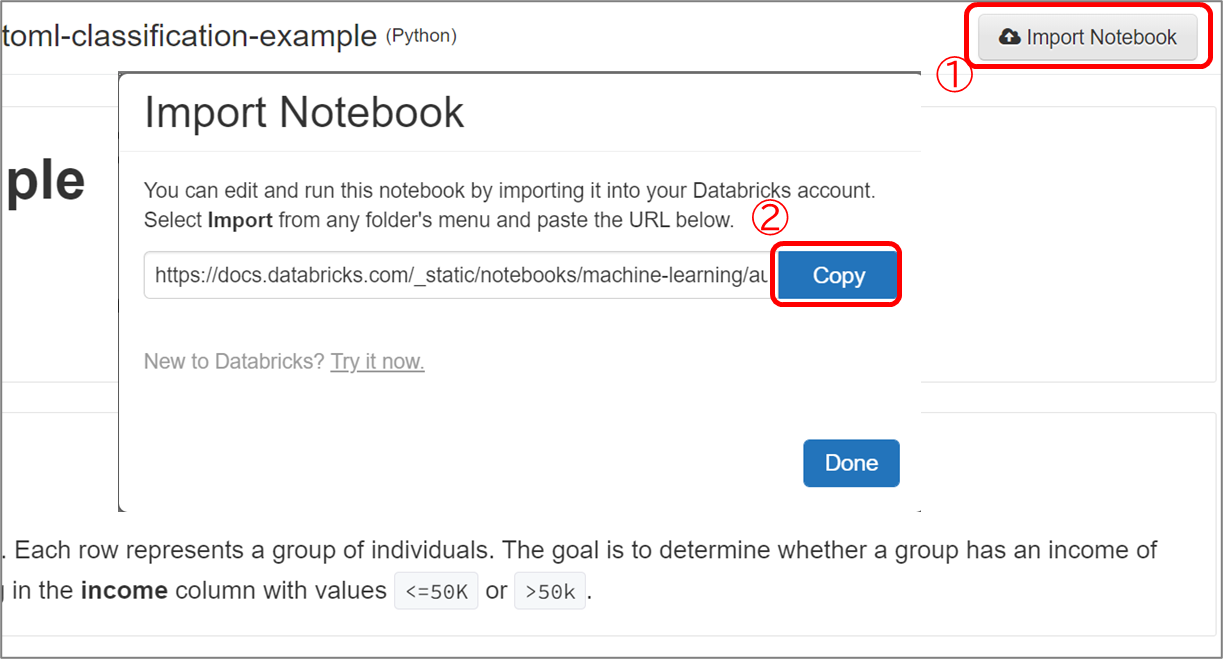 ・公式Notebook
・公式Notebook
6.[準備]公式Notebookをインポートする
自身のワークスペースから公式Notebookをインポートします。
 ① 右Navの「ワークスペース」を選択
① 右Navの「ワークスペース」を選択
②「ホーム」を押下
③ アドレス横の「∨」を押下
④「インポート」を押下
⑤ 開いたウィンドウ内のインポート元で「URL」を選択
⑥ URLを貼り付けて「インポート」を押下
7.[準備]Notebookにクラスターを接続する
DatabricksのNotebook実行には、裏側のコンピューターリソースであるクラスター(上の4で作成したもの)を接続する必要があります。
右上の接続から作成したクラスターを選択して、クラスター名が表示されるまで待ちます。coffeetime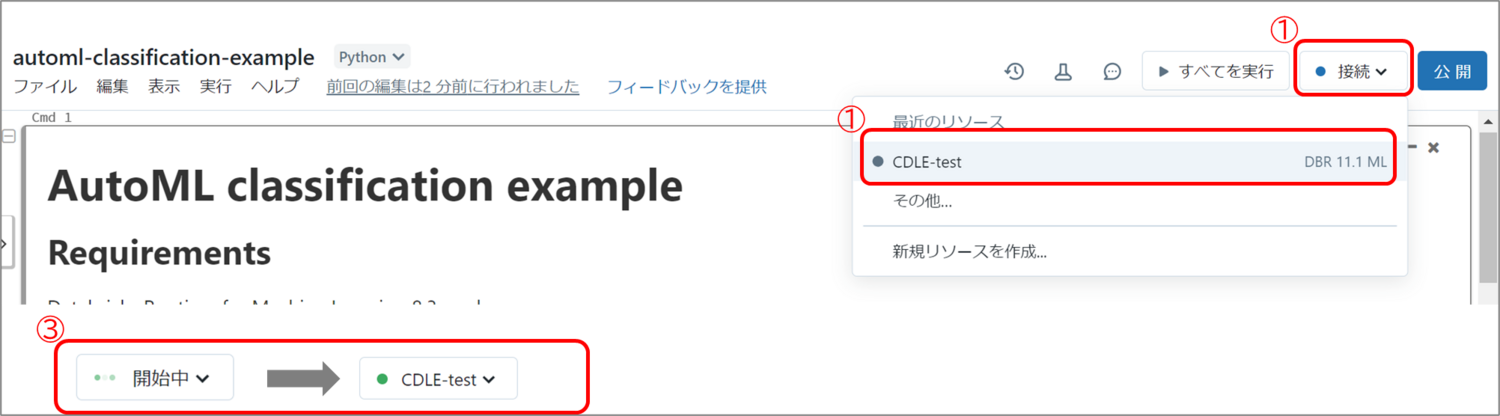 これでNotebookが動かせます。文章にすると長かったですが、クラスター立ち上げや接続の時間以外は簡単に終わります。
これでNotebookが動かせます。文章にすると長かったですが、クラスター立ち上げや接続の時間以外は簡単に終わります。
8.run!
今回はクラス分類です。データの「income」がターゲットで、年収が 50,000を超えるか否かを予測します。(今回のコンペであれば、延滞するか、しないかですね)
Trainingの部分で第一引数にtrainデータ※、分類したい列(target_col)、実行時間(timeout_minutes)を指定します。今回のNotebookでは30分が指定されているようです。
実行時間を確認したら「すべてを実行」を押下です。
※ 通常、モデル学習の際には学習につかうデータ(狭義のtrainデータ)とモデル検証データ(validationデータ)に分けますが、AutoMLではそこも自動で行ってくれるため、testデータ以外をすべて投入します。
9.結果の確認
ジョブが完了すると「MLflowで1件のランのジョブがエクスペリメントに記録されました」と表示されます。
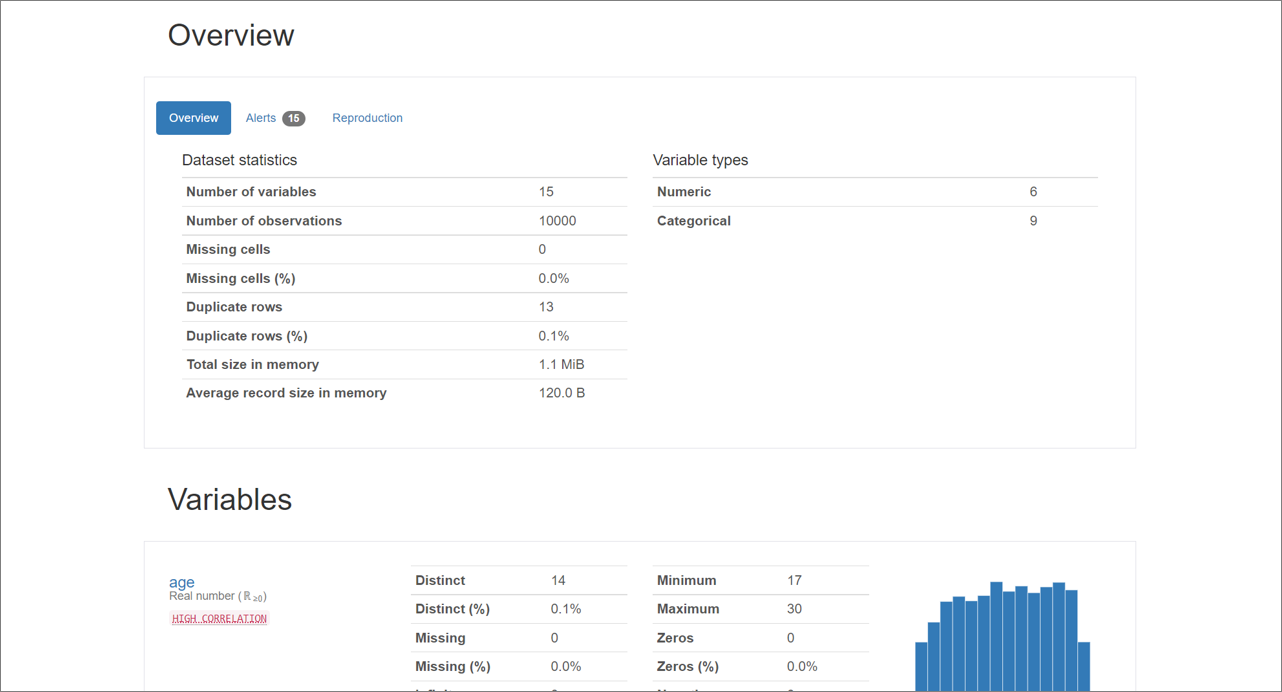
その下にある「data exploration notebook」をクリックすると、PandasProfilingの結果を確認してデータの概況を知ることができます。

エクスペリメントをクリックするとモデルの結果が確認できます。 今回は76モデルが学習され、f1-Scoreで見るとLightGBMが強かったようです。
今回は76モデルが学習され、f1-Scoreで見るとLightGBMが強かったようです。
評価指標はf1-Score以外にもAccuracy(正解率)や今回のコンテストの評価指標であるAucも見ることができます。(val_* から始まる指標で確認する点注意)
実際に学習されたモデルを確認するには、「Source」にあるNotebookをクリックします。 ① 並び変える評価指標の選択
① 並び変える評価指標の選択
② 各モデルの学習に使われたNotebookの表示
モデルのハイパラメータも自動でチューニングしてくれています。助かります。 前処置部分のPiplineもGUIで確認できます。
前処置部分のPiplineもGUIで確認できます。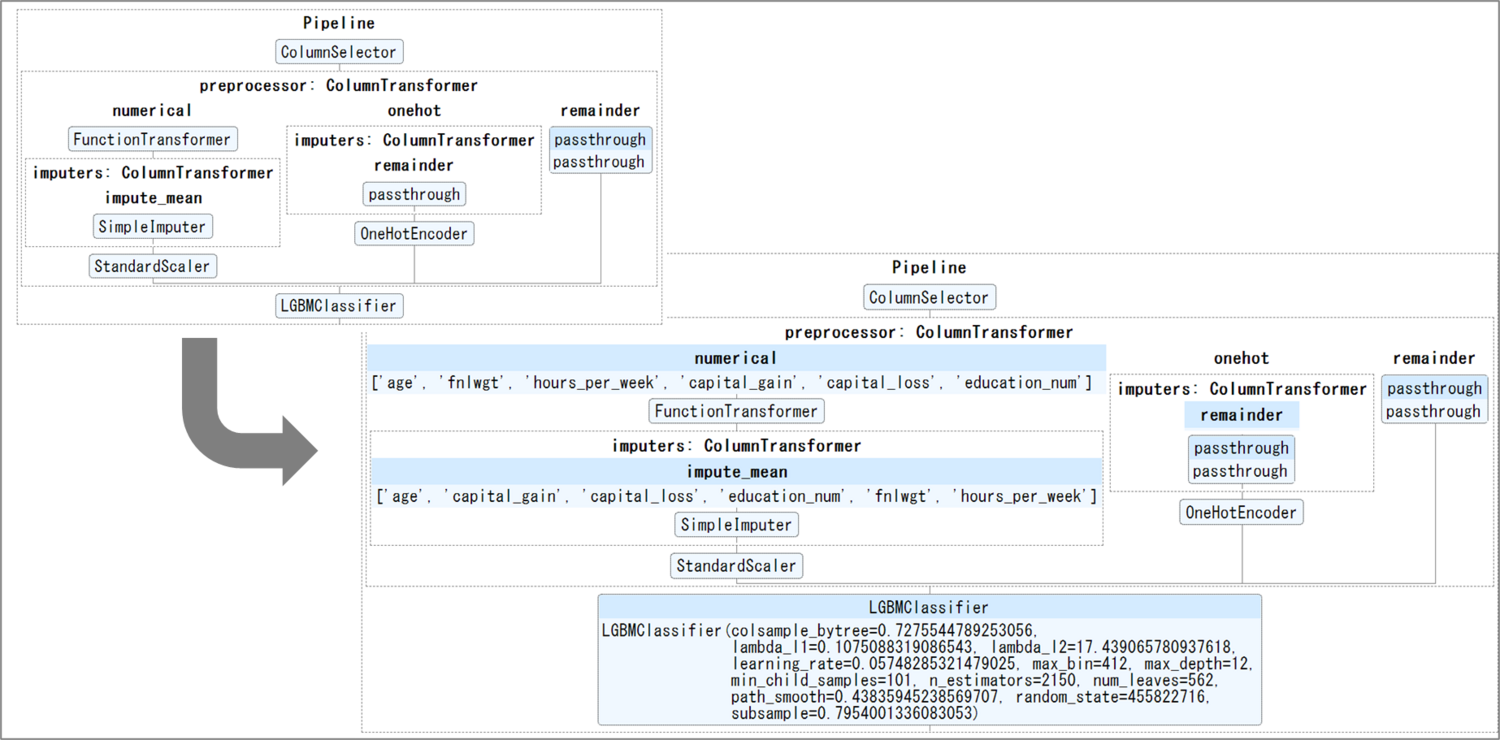
categorical: カテゴリカルな値を含むカラム(例えば、IDとして取り扱われる数値)です。
numeric: 数値を含むカラム(例えば、数値にパースできる文字列)です。
datetime: タイムスタンプの値を含むカラム(タイムスタンプに変換できる文字列、数値、日付の値)です。
text: 英語テキストを含む文字列カラムです。
onehot: 質的データのダミー変数化(種類を列にとって0-1化)
remainder: そのまま
出典: 公式ブログ(ただし、図中に存在した下線部分を筆者追記)
また、下の方にある「shap_enabled」を「True」にしてNotebookを再実行することで、特徴量の重要度を確認することもできます。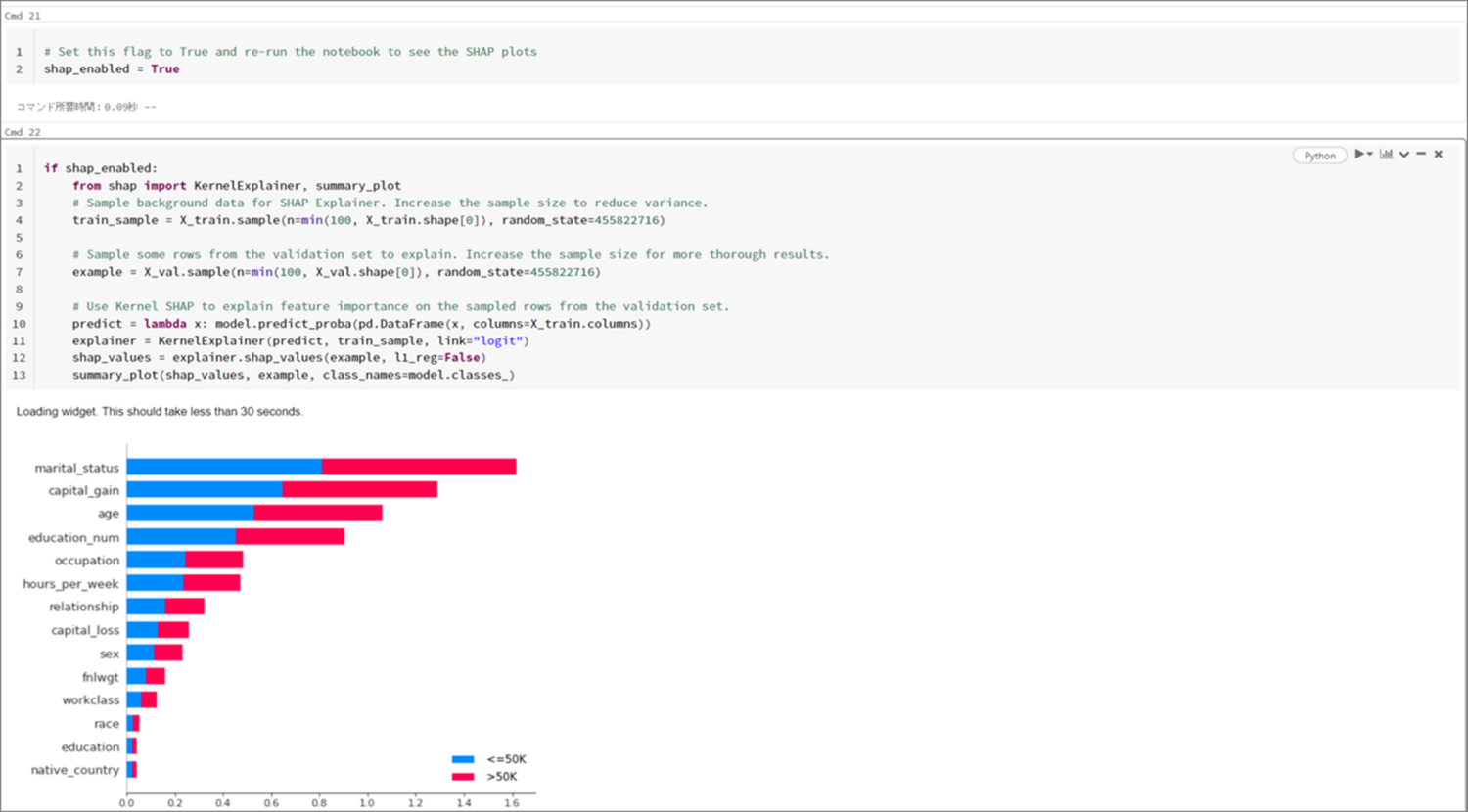
10. 推論
summary best_trial model_pathで予測結果が一番高いモデルのパスを取得できます。 個別のモデルを使う場合には、エクスペリエンスで表示される各モデルの「Models」からフルパスを取得できます。
個別のモデルを使う場合には、エクスペリエンスで表示される各モデルの「Models」からフルパスを取得できます。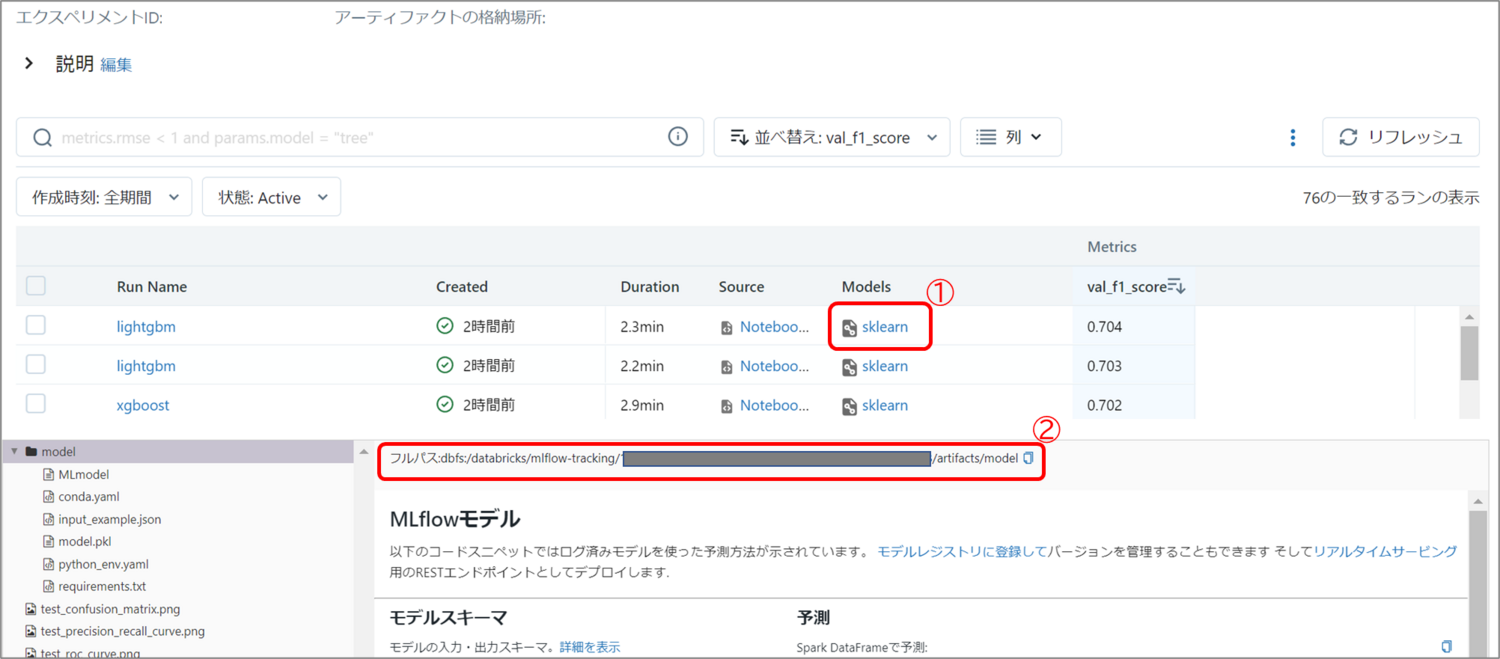 取得したパスを model = mlflow.pyfunc.load_model(**パス**) でロードし、predictを実行するだけです。
取得したパスを model = mlflow.pyfunc.load_model(**パス**) でロードし、predictを実行するだけです。
今回は、予測結果が income_predicted としてDataFrameに追加されます。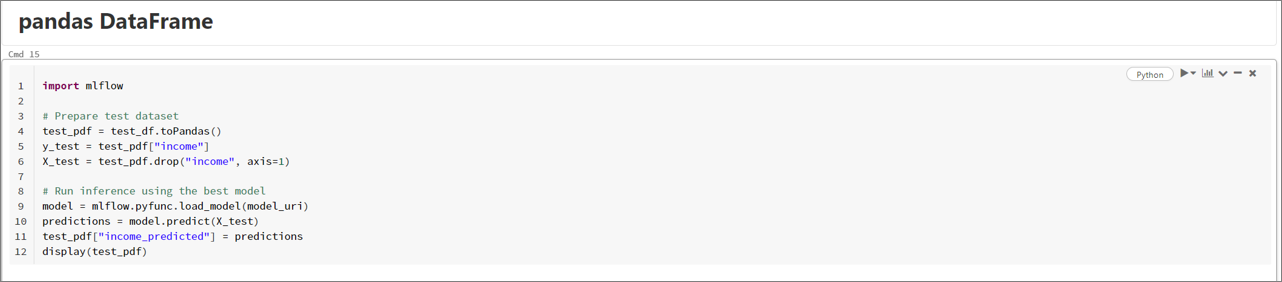
11.(参考)AutoMLで訓練対象となるモデル一覧
 出典: How Databricks AutoML works
出典: How Databricks AutoML works
12.(参考)分類タスク以外の公式Notebook
・回帰・時系列予測
13.最後に
DatabricksのAutoMLを使用してみました。
コンテスト提出の際には「前処理」「学習」「予測」の3つのコードを提出する必要があるため、エクスペリメントで表示される各モデルのNotebookの中身を自分で移植する必要があるかもしれません。(見た限りは前処理部分含め、最適化以外はsklearnで処理されているようなのでそのまま移植できるはずです)
PandasProfilingから前処理、ハイパラメータチューニングまで何も考えずに実行できる点は魅力です。
最後にご興味があれば、まだデータも公開前でタイミング的にディスアドバンテージないので皆さんも参加してみてはいかがでしょうか。G検定やE検定で学んだ知識の実践の場としていいかなとも思います。AutoMLのモデルアンサンブルや追加で特徴量を作ると強そうですね。
・公式ドキュメント(AutoML)・Databricksクイックスタートガイド(日本語)
おわり。