前回の予告通り今回は「良品のみ学習して不良品を検出する」方法です。
手法は色々あるのですが「変分オートエンコーダ」=VAEという手法を前提にお話をします。VAEはオートエンコーダに似た深層生成モデルで、潜在変数を介してデータ生成されますが真のデータ分布が複雑で求められない為、低次元空間に写像して・・・ ・・・何言っているんでしょうか?何かの暗号です。さっぱり頭に入ってきません。
・・・何言っているんでしょうか?何かの暗号です。さっぱり頭に入ってきません。
理論はおいといて、まずは「なんとなく」のイメージから考えてみましょう。
AIで例えば画像認識(分類)行う場合「この画像は犬」「この画像は猫」「この画像は工作機械」など、学習する画像に対してラベル(正解)をつける必要があります。
凄く大変です。猫か犬か分からない画像が出てきたりするとストレスマックスです。
ですが、今回は「良品のみ学習」です。学習する画像データは全て良品です。何を見ても良品なのでラベルもアノテーションも不要です。
前者が「教師あり学習」後者が「教師なし学習」となります。G検定等でお馴染みですね。 ここでまた前回に引き続き警官の登場です。新米警官です。
ここでまた前回に引き続き警官の登場です。新米警官です。
新米警官は善良に生きて来たので善良な一般人(良品)は学習していますが、犯罪を起こすような怪しい奴の具体的な姿(不良品)を知りません。
その為、善良な一般人とは異なる姿をしていたら「怪しいやつ!」と思い、それを異常と検知する。これが基本的な考え方です。 警官の頭の中では何が起こっているのでしょう?
警官の頭の中では何が起こっているのでしょう?
実際に見た(学習した)様々な善良な一般人が警官の頭の中に記憶されています。 この記憶は広い空間のような場所に分布されるように警官の頭の中に配置されていきます。そして、目の前の人物が怪しい人物かどうかを判定するとき、この頭の中のどのあたりの人物と同じ感じなのかをまず探します。
この記憶は広い空間のような場所に分布されるように警官の頭の中に配置されていきます。そして、目の前の人物が怪しい人物かどうかを判定するとき、この頭の中のどのあたりの人物と同じ感じなのかをまず探します。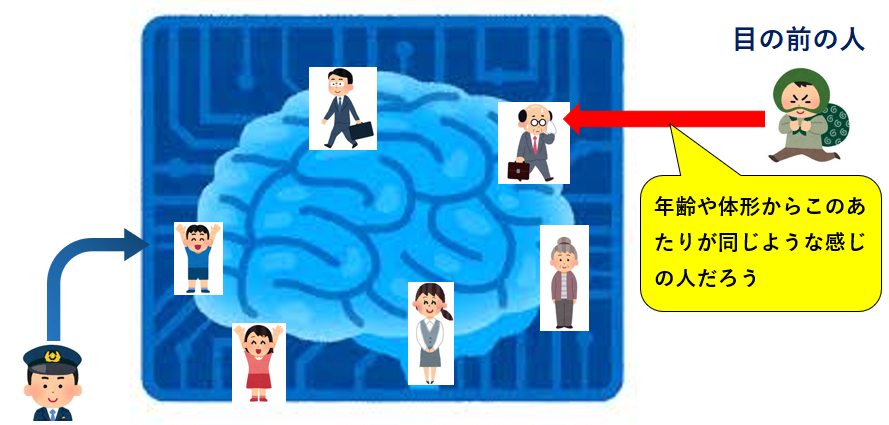 「それ知ってる!画像検索でしょ!」と思われるかもしれませんが、さすがにAIなので内部でもっと複雑なことが行われています。
「それ知ってる!画像検索でしょ!」と思われるかもしれませんが、さすがにAIなので内部でもっと複雑なことが行われています。
実際に記憶していない人物についてもハッキリとではないですが、警官の頭の中で記憶した人物の間にある人物として想像することが出来ます。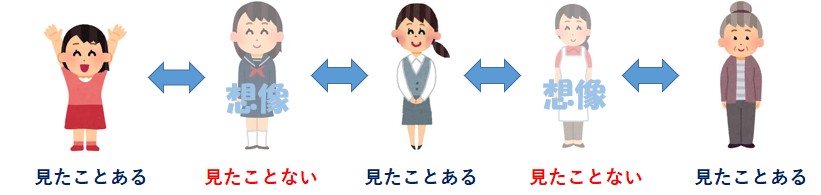 例えば目の前にいるのが女学生に見える場合、善良な女学生は見たことがなくても、警官は何となく想像が出来ます。そして、警官は目の前にいる女学生を、想像した「善良な女学生」のイメージに徐々に近づけていきます。
例えば目の前にいるのが女学生に見える場合、善良な女学生は見たことがなくても、警官は何となく想像が出来ます。そして、警官は目の前にいる女学生を、想像した「善良な女学生」のイメージに徐々に近づけていきます。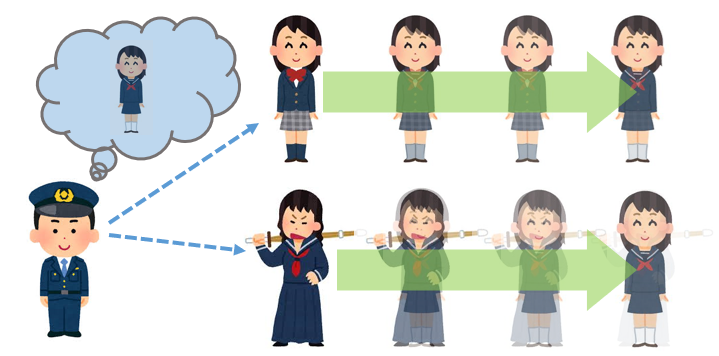 どれぐらい近づけるかは、警官がどれぐらい厳しく取り締まりを行うか?という厳しさによって変わってきます。
どれぐらい近づけるかは、警官がどれぐらい厳しく取り締まりを行うか?という厳しさによって変わってきます。
目の前の人物と、善良な女学生に近づけたイメージを比べてみましょう。差異が大きいなら不審者です。怪しいので職務質問をして確認しましょう。 職質してみると善良な女学生という事が分かりました。異常検知で言えば良品です。
職質してみると善良な女学生という事が分かりました。異常検知で言えば良品です。
その経験を記憶し、新米警官はひとつ賢くなりました。(追加学習) こうして、善良な一般人(良品)を覚え、立派な警官になることを目指していきます。
こうして、善良な一般人(良品)を覚え、立派な警官になることを目指していきます。
ほぼ間違わなくなったら、どこの現場に出しても恥ずかしくない立派な警官・・・異常検知システムになっていることでしょう。
「良品のみ学習して不良品を検出する」イメージはこのような流れとなります。
簡単に感じますが学習・検知する過程において、様々な問題が発生します。
このあたりについて、次回説明できればと思います。


2022/08/28 11:44
異常検知についての考察②



28リアクション
このブログ一覧は
メンバー投稿記事
ですメンバー登録すると、限定記事の閲覧やメンバー同士の交流、限定イベントへの参加などができます。
CDLEコミュニティサイトβ版
JDLA(一般社団法人日本ディープラーニング協会)が実施する、G検定・E資格の合格者のみが参加できる、10万人を超える日本最大級のAIコミュニティ「CDLE」の紹介サイトです。 CDLEでは、ディープラーニングの社会実装の日本代表として、社会を発展させるエバンジェリストたちが集まり、学び合い・アウトプットする場を提供しています。
詳細を見るCDLEメンバー
¥55/月(税込)
登録情報を確認の上、事前登録された方へ本登録のご案内メールを送信します。もっとみる閉じる
登録情報を確認の上、事前登録された方へ本登録のご案内メールを送信します。
28リアクション
メンバーの方はこちらからログイン