


OpenAIより「4o Image Generation」というサービスが提供されました!
OpenAIの英語のページを翻訳してまとめると下記のような内容でした。
OpenAIは、言語モデルにおける画像生成を中核機能と考え、GPT-4oに最先端の画像生成技術を搭載しました。これにより、ただ美しいだけでなく、実用的で意味のある画像が簡単に作れるようになりました。
GPT-4oの画像生成は、文字や図、ストーリー性のある絵など、情報伝達や創作に役立つビジュアルを正確に表現できます。たとえば、ポスターや白板のメモ、科学の実験図、招待状やレストランメニューなど、現実に使える画像を自然な文脈で生成できます。また、ユーザーの指示やアップロード画像に基づき、対話を通じて画像を細かく調整することもできます。
このモデルは複数のオブジェクトや文字を含む複雑な構図にも強く、情報性とデザイン性を両立した画像を得意としています。一方で、細かい文字の再現や顔の一部だけを編集するといった繊細な調整はまだ課題も残っており、今後改良が進められます。
安全性にも配慮されており、ポリシーに反する画像の生成はブロックされ、生成された画像には出所を示すデータも付与されています。
GPT-4oの画像生成は、チャットするだけでプロ品質のビジュアルを簡単に作れる新しい創造ツールとして、あらゆる分野に広がりつつあります。
ここで、勘違いしている方もいるかもしれませんので、補足しておきます。
「DALL-E3とは別物です!!」
なので、ChatGPTのDALL-Eを操作して「変わってないじゃん!」って言っている人がいましたら…当たり前です!
全く別の仕組みなのですから…
間違えずにGPT-4oを選びましょう!
ChatGPTさんにGPT-4o Image GenerationとDALL·E 3の違いを聞いてみました。
※間違ってたらご指摘下さい!
GPT-4o Image GenerationとDALL·E 3の主な違いは、画像生成の統合度と技術的アプローチにあります。
1. 統合度の違い:
DALL·E 3は、ChatGPTに外部の画像生成モデルとして組み込まれていました。一方、GPT-4o Image Generationは、GPT-4oモデル自体に画像生成機能がネイティブに統合されています。これにより、テキストと画像の連携がよりスムーズになり、ユーザーは特別な設定やツールを使わずに、ChatGPT上で直接画像を生成・編集できるようになりました。
2. 技術的アプローチの違い
DALL·E 3はDiffusion(拡散)モデルを採用しており、画像全体を一度に生成する手法を取っています。これに対し、GPT-4o Image GenerationはAutoregressive(自己回帰)モデルを採用し、画像を左から右、上から下へと順次生成します。この違いにより、GPT-4oは画像内のテキストレンダリングや複雑なプロンプトへの対応力が向上しています。
これらの進化により、GPT-4o Image Generationは、より高精度で柔軟な画像生成を実現しています。
なるほど。全然違う事が分かってきました。
@Y.Miyadoさんが、いち早く、この技術を使って漫画を描かれていました。
私も、いろいろ他に「やること」が山積みなのですが…
それでも、いてもたってもいられなくなり、つい私も漫画を作成したくなり…
やってみました!
やっちまいました!!
まだ、慣れないのですが…凄いですねこれ!!
漫画の元ストーリーは下記の物語になります。
この訳の分からない、支離滅裂的な物語がどのように漫画になるのか?
非常に楽しみですね✨

“The Quantum Butterfly Dances in the Turbulence”
〜量子の蝶は乱気流に舞う〜


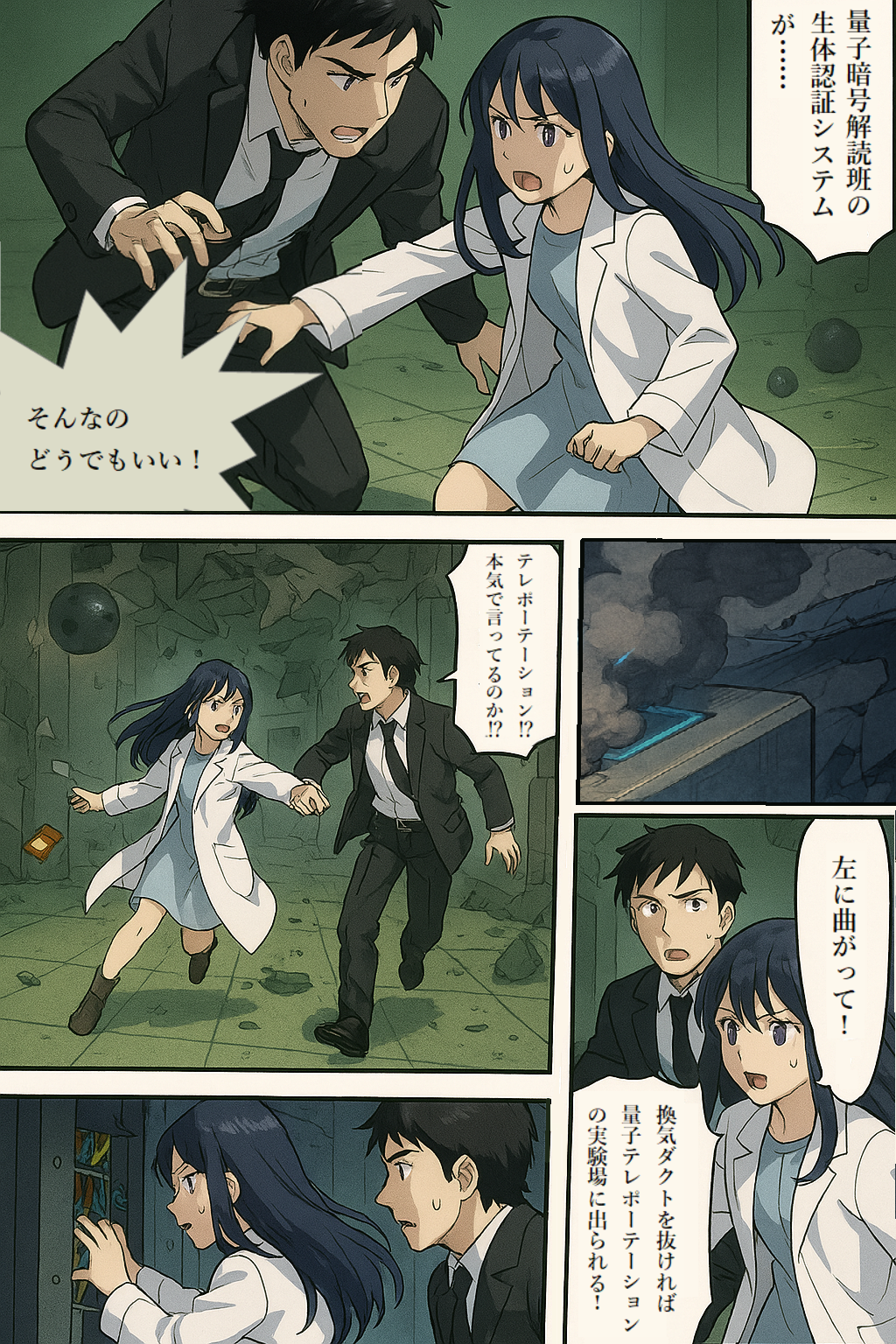








漫画はここまでです!
続きは小説で呼んでください!
「4o Image Generation」のプロンプトの使い方も全然慣れておらず、1日もかけずに即興で作成した漫画ですが、ここまで作成できてしまいまいます。
天才プログラマー瑠璃羽のキャラクターは安定していますが、男性キャラクターである蓮の方は安定していない感じですね!
絵柄が安定しないことも含めて、ここはプロンプトが不足しているような気もしています。
学習漫画ぐらいだったら、アッという間に完成できそうです!!
まだ、これで発展途上っていうんだからスエオソロシイ…
ぜひ、みなさんも作成してみて下さい!!
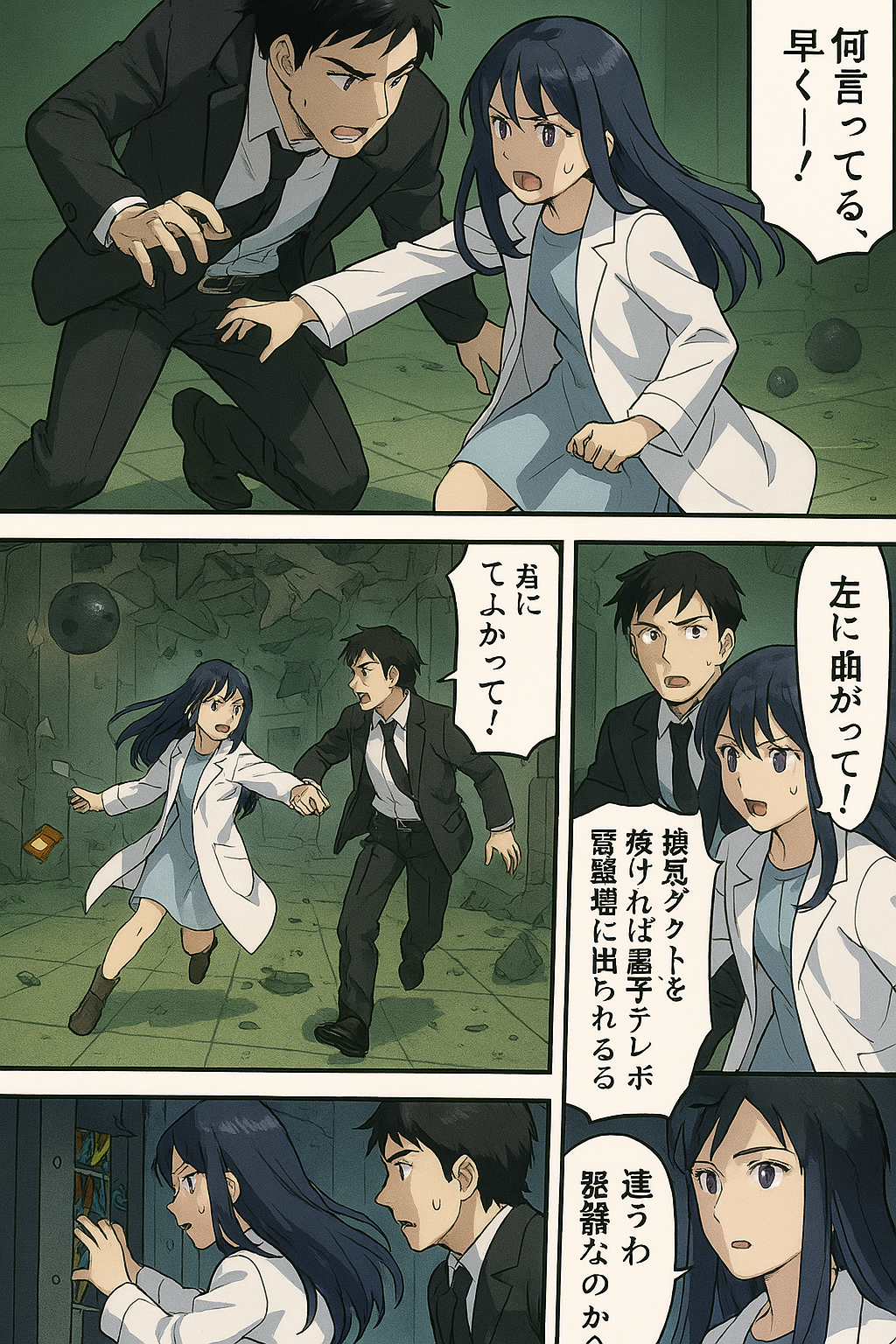
編集前の元絵も貼っておきます
こんな感じで生成されたものを編集しました!









以上です!!
3回に一回ぐらい瑠璃羽が眼鏡をかけて登場するので、それについては再作成をさせています!
【参考】