



よこぼと申します。
超初心者です🔰
同じような初心者・初学者の方にも、
育成や普及活動を進める立場の方にも、
参考になるような記事をあげていけたらと思います。
よろしくお願いします🙇
※広義のAIプログラミングだよな(うんうん)と思い、コミュニティ「AIプログラミング」で公開しました!
=======================
今回チャレンジするのは、
「世界に色をつける‼️」(かっこよ)
白黒画像をカラーにしよう、という試みをしました🔥
はじめに壮絶なネタバレをすると、失敗してます😱
でもいいじゃないですか、成功だけが全てじゃありません😭
というわけで、本編まいります❗️
=======================
毎度のことながら、超初心者のためコード書けません。
GPTさんにお願いしてます、いつもありがとう。
今回はGoogle colaboratoryを使いました。
(途中からGPU使いすぎによりkaggleに切り替えてます)
こんなことcolaboでできる?と聞いたら、すぐにカード作ってくれるGPTさんすごい😍
本題に入る前にちょっと色の話をします。
そもそも色ってどういう指標があるんだろう?
有名なのはRGB(赤緑青)ですが、
今回は"Lab"という表し方を使います。
ざっと説明すると、
L*:明るさ
a*:緑〜赤
b*:青〜黄
を数字で表したものです。
(*は気にしないでください。よくわからない)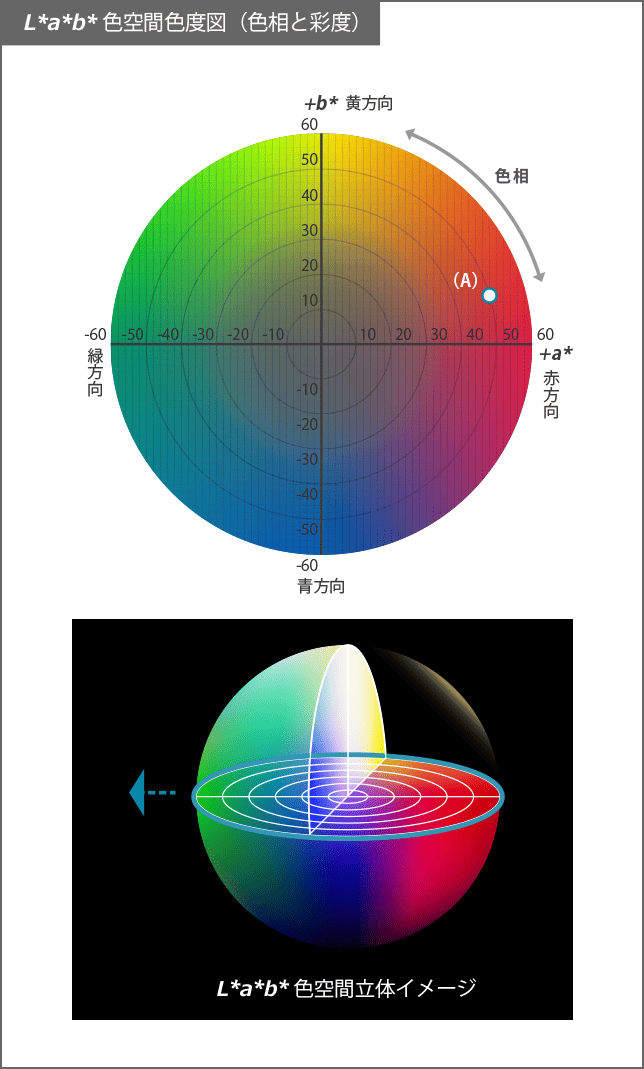 https://www.konicaminolta.jp/instruments/knowledge/color/section2/2-02/
https://www.konicaminolta.jp/instruments/knowledge/color/section2/2-02/
なんでLabを使うのか?
それは、今回の白黒画像(グレースケール)が、L*(明るさ)のみわかった状態だからです。(a*、b*はゼロ)
「Lab」は、明るさを1つのパラメータ(L*)として扱いますが、
RGBは明るさと色が混ざった指標なので、
今回の目的と相性が悪いんですね。
だからLabを使います。
今回は『モデルを学習させてabを予測させる』がゴールです🔥🎨
モデルはこんな感じ。
U-NET型らしいです。
(別に僕が"U-NET型にしてくれい"とかお願いしたわけじゃないです)
入力: 白黒画像 (L)
│
▼
┌───────────────┐
│ Encoder部 │ ← 特徴抽出(画像を圧縮)
│ │
│ [Conv + ReLU] ─→ e1
│ ↓
│ [Pool]
│ [Conv + ReLU] ─→ e2
│ ↓
│ [Pool]
│ [Conv + ReLU] ─→ e3
└───────────────┘
│
▼
┌───────────────┐
│ Bottleneck │ ← 全体特徴を凝縮
│ [Conv + ReLU] │
└───────────────┘
│
▼
┌───────────────┐
│ Decoder部 │ ← 画像を復元(アップサンプリング)
│ │
│ [UpConv] + concat(e3) → [Conv + ReLU]
│ [UpConv] + concat(e2) → [Conv + ReLU]
│ [UpConv] + concat(e1) → [Conv + ReLU]
└───────────────┘
│
▼
出力: 色チャンネル (ab)
│
▼
tanhにより[-1,1]にスケーリング
このモデルを学習させて、
入力画像のabを予測させます。
学習データセットはすぐ入手できる以下の3種類を試しました。
CIFAR-100:
小さな日常物体を含む多クラス画像。学習データは50,000枚(各クラス500枚×100クラス)。
STL-10:
高解像で少数サンプルの10クラス画像。学習データは5,000枚(各クラス500枚×10クラス)。教師なし学習用に10万枚の未ラベル画像あり。
Flowers-102:
多様な花の高精細画像。学習データは約1,020枚(全体で約8,000枚)。転移学習によく使われる。
何はともあれ、やってみよう!!です。
実際にやってみた結果をごらんあれ!
ど ん !!
※左が入力、右が出力です。入力を一度白黒にしてから出力してます Cifar100で学習
Cifar100で学習 STL10で学習
STL10で学習 Flowers-102で学習
Flowers-102で学習
うーん。。。微妙。。。
STL10よりCifar10の方が若干よさそう。
Flowers-102は頑張った感がある。
なんか全体的にセピアっぽいな・・・とCifar100, STL10を使用したときに感じたので、
GPTに聞いてみたら「あるある」らしいです。
明確に色づけるより無難な色(茶色・オレンジ寄り)にした方が学習のスコアが高くなっちゃうからみたいです。
Flowers-102は他2つに比べて画像が鮮やかなので、少し期待をしていたのですが・・・
そしてそのあとも色々と格闘して、
ColaboのGPU使えなくなってkaggleを始めたりして。。。
ちなみに改善策はGPTさんに言われるがままにこんな感じのことをしました。
1️⃣ Flowers102を混ぜる:
彩度の高い実写データを10〜30%混ぜて、モデルに“色を出していい”感覚を学ばせる。
2️⃣ Perceptual Lossを使う:
VGG特徴を使って構造的な類似度を学習し、自然な色合いを再現する。
3️⃣ Chroma Pushを入れる:
ab成分の平均を上げて、無彩色(グレー寄り)に偏るのを防ぐ。
4️⃣ TV正則化を足す:
彩度を上げた時の色ムラやノイズを抑えて、なめらかに見せる。
5️⃣ 早期終了をゆるめる:
SSIMの小さな揺れで止まらないよう、patienceやmin_deltaを緩めて最後まで学習させる。
6️⃣ 画像サイズを少し上げる:
128→160などにして、色情報をより多く扱えるようにする。
みなさまには釈迦に説法かもしれませんが、注釈つけときますね(●'◡'●)
※VGG(VGGネットワーク):
画像認識に使われるCNNモデル。
中間層の特徴を使うと、人間の“見た目の近さ”を評価できる。
※SSIM(構造的類似度)
画像の「明るさ・コントラスト・構造の似かた」を見る指標。
値が1に近いほど、元画像に構造的に近い。
で、最後の渾身の1枚、ご覧ください!!!!
ええええええええええ
つらいよおおおおおおおおおおおお
すいません取り乱しました・・・
赤みがかった部分は頑張りの証です。
今回わかったこと:
白黒画像に色を付けることは予想以上に難しい。。。
思った以上に大変でした。
またリベンジしたいと思います🔥
アドバイスなどありましたら、コメントいただけると泣いて喜びます😿
ここまでお読みいただき、本当にありがとうございました!!
次回の失敗談もお楽しみに!!