


よこぼと申します。
初心者です🔰
同じような初心者・初学者の方にも、
育成や普及活動を進める立場の方にも、
参考になるような記事をあげていけたらと思います。
よろしくお願いします🙇
=======================
3Dモデルに興味津々のよこぼ
昨年に初めてのAR体験をしてからというものの、
3Dモデルは僕の興味の中心でした。
今回は、生成AIに思い通りの3Dモデルをつくってもらうことが目標です。
昨年初めて3Dモデルを作ってみた記事↓
これも3Dモデル使ったARですね↓
昨年度末からBlenderという3Dモデリングソフトにはまってます!
こんな感じで色々作って遊んでます↓
---
初めてのComfyUI
ComfyUI(こんふぃーゆーあい)は、Stable Diffusionなどの画像生成AIを動作させるための、強力で拡張性の高いノードベースのユーザーインターフェース(GUI)です。
Google AIモード さん
なぜいきなりこいつが出てくるかというと、
@nabepy さんのつぶやきでこんなものを見かけたからです。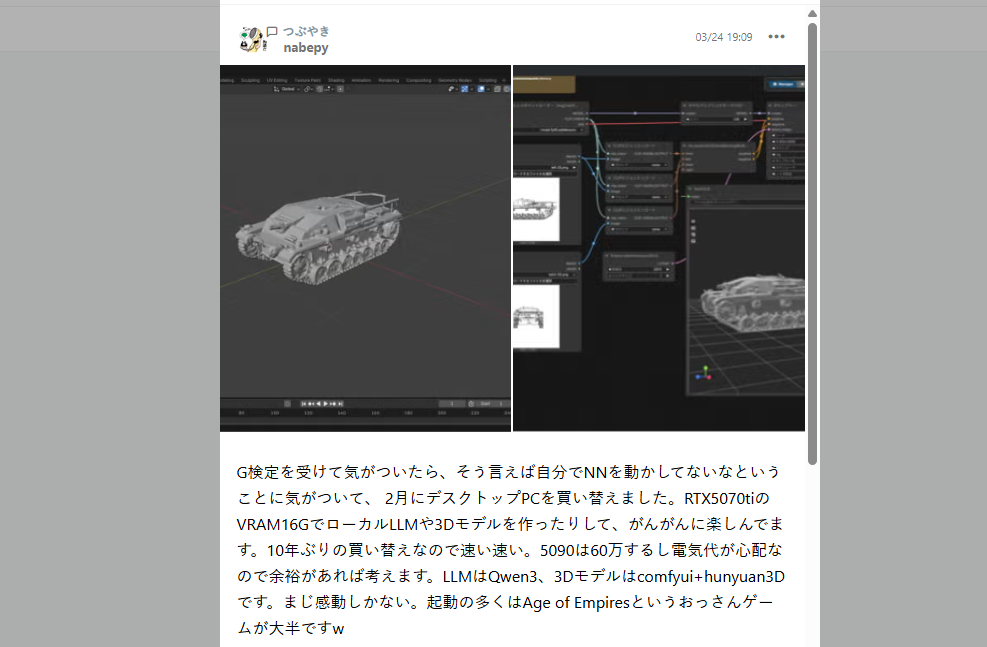
https://cdle.jp/timeline?filter=following&selector=all&message_id=11672115
このつぶやきを見かけて、
画像から戦車ができている・・・!!
すげー!!✨✨
となって、nabepyさんが紹介しているComfyUI+hunyuan3Dにチャレンジしてみました!
とまあ意気込むまではよかったんですが、
ComfyUI、素人が手を出すにはなかなかのくせもので・・・
デスクトップ版を入れたらうまくいかず、インストールしたり関連ライブラリをなんちゃらしてどんちゃん騒ぎしたのちにようやく動くところまで持っていけました・・・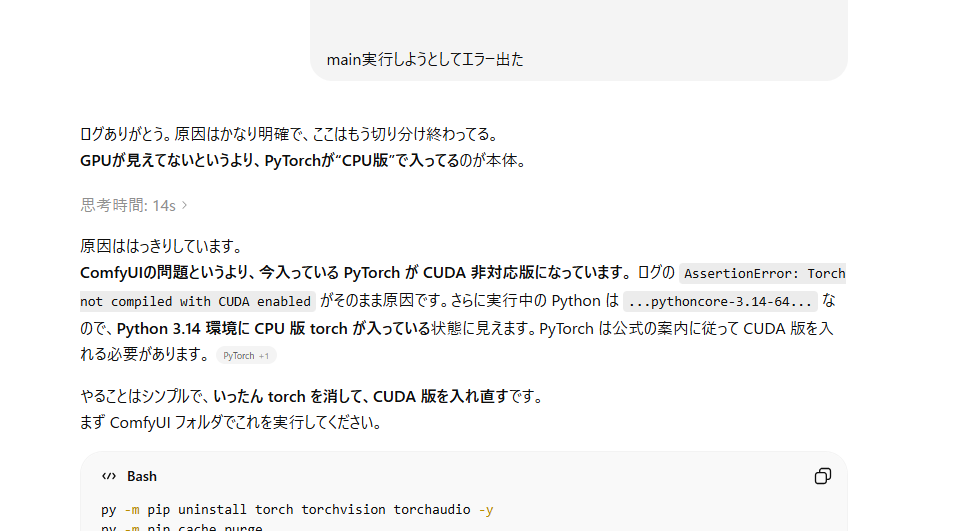 ※言葉では言い表せないので苦悩のほんの一部をお届け
※言葉では言い表せないので苦悩のほんの一部をお届け
---
レッツ3Dモデル作成!
とその前に、
せっかくこんな面白そうなものを手に入れたので、
画像生成でもやってみるか。
ビギナー向けのワークフローで画像を作ってみました。
プロンプトは「かっこいいアンキロサウルスの画像作って!」みたいなやつです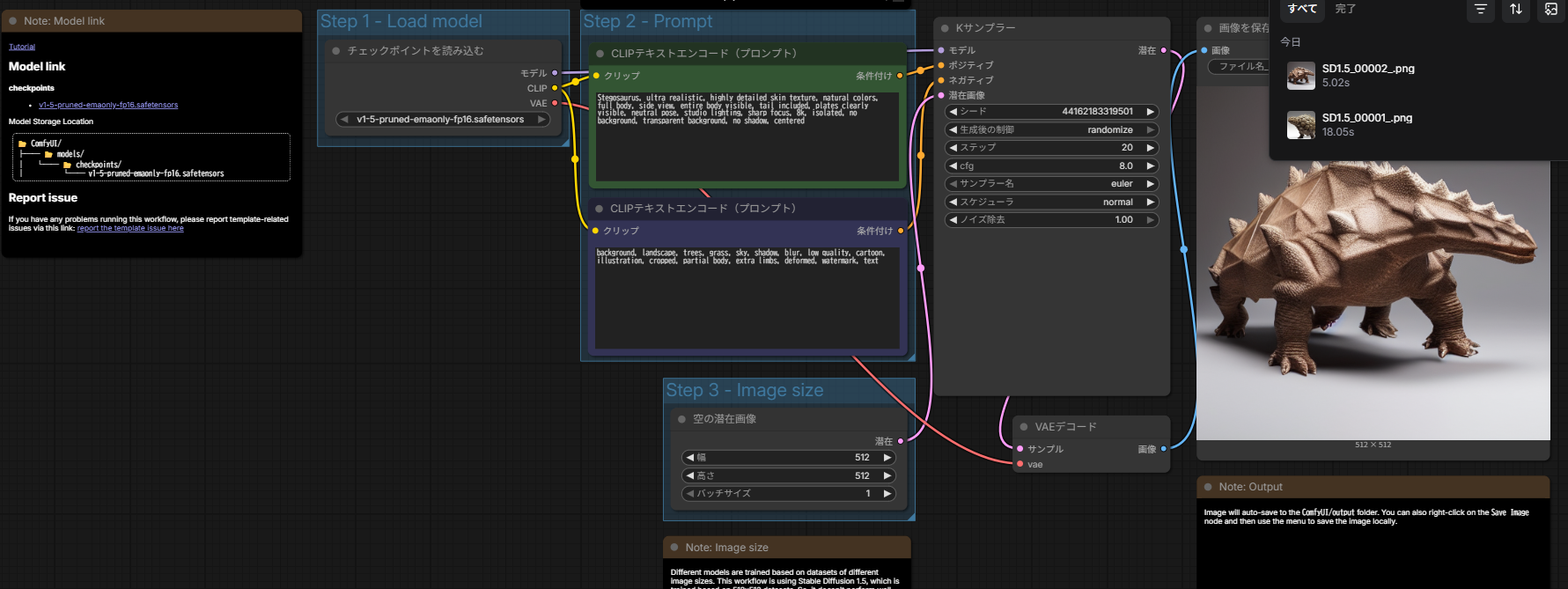 がーん・・・
がーん・・・
きもちわる・・・
と思ったら、モデルが"v1-5-pruned-emaonly"というStable Diffusion初期に導入されていたものでした。
なーんだ、それは仕方がない。
気を取り直して3Dモデルを作ります。
今回使用するのはHunyuan3D
僕はなんて発音すればいいのかいっつも迷っています。ふんいぇん?
で、入力はNanobanana2に作ってもらったステゴサウルスです。
さあ!実力を見せてくれ!!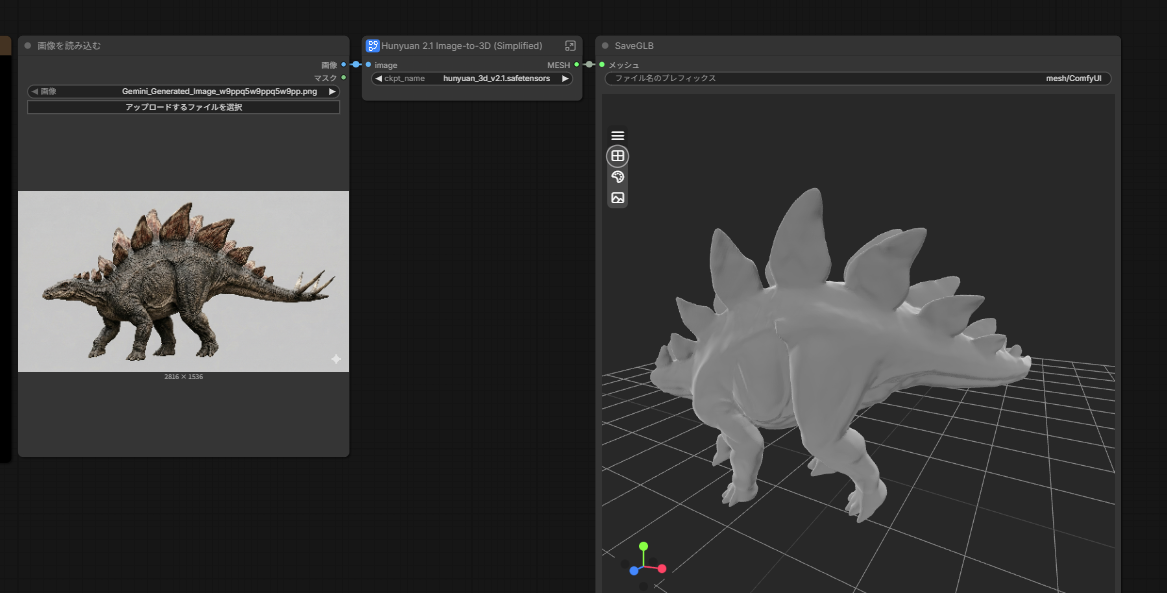 でん!!
でん!!
ものの2m20sでできましたよ!
すげー!! でん!
でん!
くびがない!
うーん、
首は欲しいよなぁ・・・
と思案した結果、
思い出したんです。
nabepyさんは複数の画像を入れていましたよね。
だから僕も複数画像を入れればいいのでは?!
と思ってGeminiに作らせ始めたんですが、地味にめんどい。
あっ!
せっかくなら、
複数視点からの画像を作るワークフローを作ってみたらいいのでは?!
ということで作ってみました。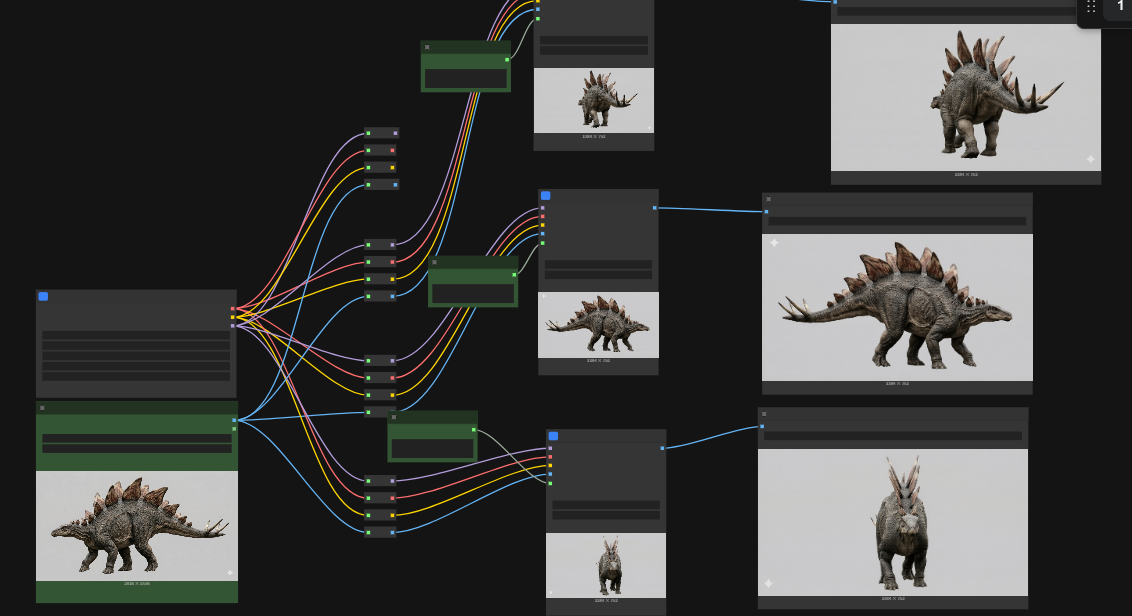 でん!
でん!
そしてこれをこうする。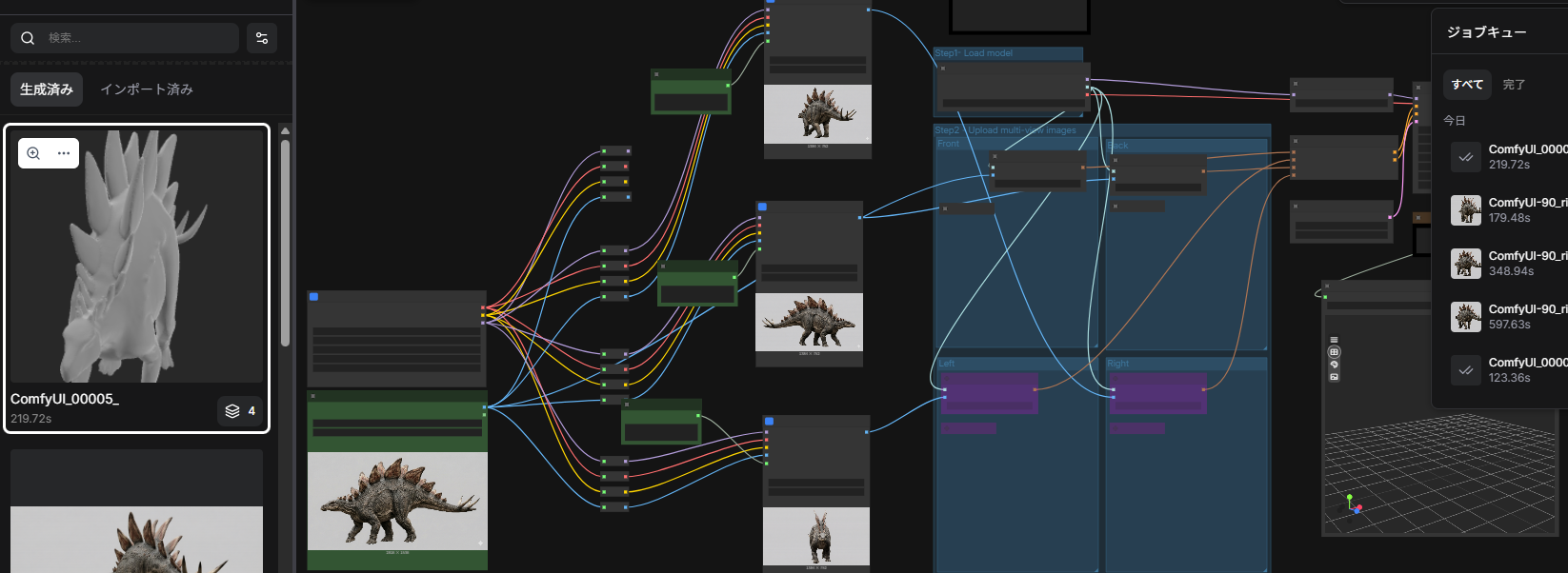 ちょっとスクショがうまくいかなくてわかりにくいですが(-_-;)、
ちょっとスクショがうまくいかなくてわかりにくいですが(-_-;)、
「左半分で複数視点からの画像を作り、右半分で4つの画像をもとに3Dモデルを作る」
というフローになっております。
で、肝心の3Dモデルはこちら
おお!!
少なくとも頭はありますね!
なんかいい感じっぽい!!
参考動画です。
(ちょっと小噺:この動画は16倍速なので実際は5分ちょっとかかります。さらにこの動画は後どりなので、条件は一緒ですが上の画像のモデルの方がうまくいきました。なんかよく見たらしっぽ二股になってるし・・・)
---
こんな感じでComfyUIでの遊び生活が始まったわけです。
感想を一言で。 と言われたら
「ただただ楽しい」
それだけです。
やっぱり色々なモデルを触るのって楽しいですね、
画像生成も実はここで紹介した以外にちょこちょこ遊んでおります。
さあ、次回はテクスチャ(色)を付けていこうと思いますが・・・
なかなか難航する予感(というか難航中です)
ここまでお読みいただきありがとうございました!!
また次回もよろしくお願いします!!