




高品質な画像生成ができるStable Diffusionが盛り上がっていますね。使い方については色々な場所で情報が手に入るのですが、動いている「仕組み」に関する情報は少なかったので、簡単に調べてみました。
名前に「Diffusion」が付いているから、GoogleのImagenとかでも使われている「Diffusion Model = 拡散モデル = ノイズ画像から画像を生成していく手法」が利用されていることは予想できますが、実際は「ちょっとした(画期的な?)工夫」が加えてありました。
🧨Stable Diffusionの一番のポイント
Stable Diffusionの最大のポイントは「Latent Diffusion Model(潜在拡散モデル)」が使われているという点です。
Latent Diffusion Modelは「High-Resolution Image Synthesis with Latent Diffusion Models」というタイトルの論文で発表された物であり、Stable Diffusionの実体は、ほぼほぼ、この「Latent Diffusion Model」です。(そのため、Stable Diffusion自体の論文は存在せず、Stable Diffusionを調べた先に行き着くのが、このLatent Diffusion Modelに関する論文になります)
https://arxiv.org/abs/2112.10752
🧿Latent Diffusion Modelの概要
Stable Diffusionの実体は「Latent Diffusion Model」という事で、論文中の図(Figure 3)を引用しつつ、Latent Diffusion Modelの特徴についてお伝えしたいと思います。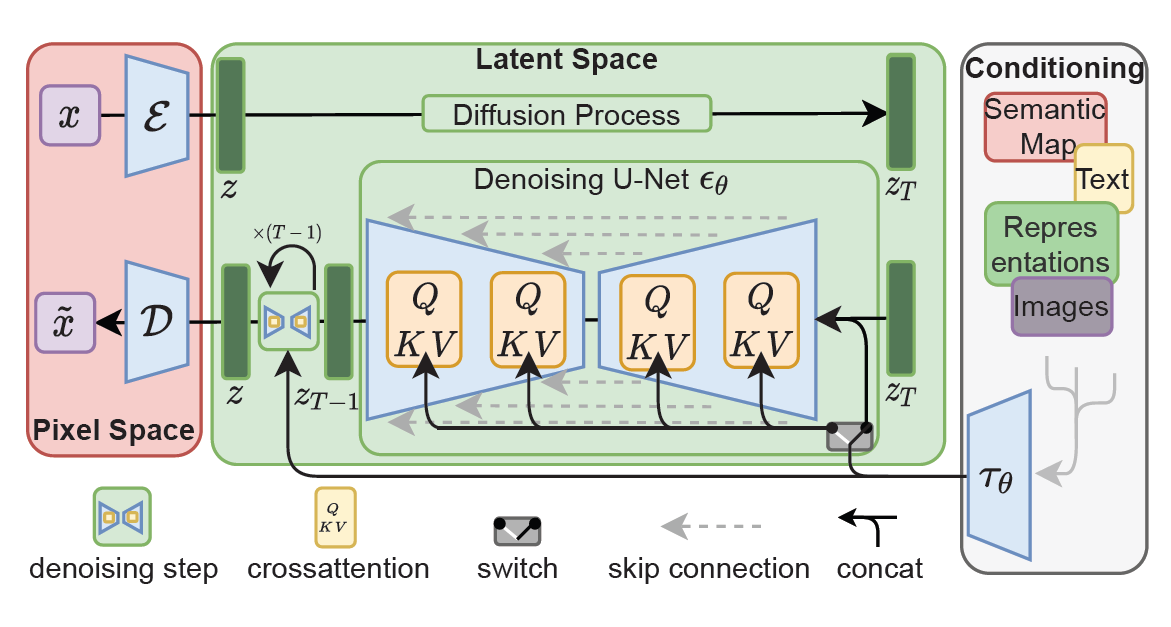 まずは、モデルが大きく3つの領域(左のPixel Space、真ん中のLatent Space、右のConditioning)に分かれていますが、コアとなるのは「真ん中のLatent Space」という部分になります。
まずは、モデルが大きく3つの領域(左のPixel Space、真ん中のLatent Space、右のConditioning)に分かれていますが、コアとなるのは「真ん中のLatent Space」という部分になります。
Latent Spaceというのは「潜在空間」を指しており、Auto-encoderであるVAE(Variational Auto-Encoder)のエンコーダで得られる「潜在変数」を中心に扱っている領域です。
一般的なDiffusion modelは、実際のRGB画像(Pixel Space)に対して処理を行うため「処理に必要なメモリ量や計算量が膨大」になり、実際の学習や推論に利用する事は困難になります。(Googleのように膨大な計算リソースを持っていれば力業も使えますが・・・)
そこで「画像を直接使うのではなく、VAEで圧縮して低次元になった潜在変数に対して」Diffusion modelを適用する・・・というアプローチが、このLatent Diffusion Modelです。
具体的な例を挙げると、形状が(3, 512, 512)の画像は、VAEで(3, 64, 64) の潜在変数に変換されるため、メモリ消費量を画像を使うときに比べて「1/64」に抑えることができます。潜在空間では次元数も減っているため、当然計算に必要な時間も大幅に短縮できます。
🧿Latent Diffusion Modelの構成要素
上の説明ではざっくり過ぎたので、もう少し細かい部分も見ていきましょう。
① VAE(Variational Auto-Encoder)
概要図の左側にある「Pixel Space」部分で使われている部分で、役割としては「画像→潜在変数」、「潜在変数→画像」への変換を行う部分です。
Latent Diffusion Modelは「潜在変数」に対して処理を行うものなので、画像情報を潜在変数に変換する必要があります。この部分を、図中で「E」と記載してあるVAEのエンコーダで行っています。
また、Diffusion Modelを使って文章から生成される画像は「潜在変数」の状態なので、潜在変数から画像に戻す処理を、図中の「D」と記載してあるVAEのデコーダで行っています。
② U-Net
画像のセグメンテーションで有名なU-Netですが、Stable Diffusionでは「潜在空間(Latent Space)上で、段階的にノイズを除去」するために利用されています。(ここで扱っているデータは、全て潜在変数の形であることに注意)
Latent Diffusion Modelで使われているU-Netは、一般的なU-Netと違い、「cross-attention」という形で、外部からの条件(例えば入力したテキストの指示)を与えられるような仕組みになっています。
簡単に言うと、このcross-attentionの仕組みによって、生成したい画像の内容をコントロールできるようになっているイメージです。
ノイズを除去していく過程で、このU-Netを50回くらい通すことになりますが、Stable Diffusionでは、この時に色々なスケジューラアルゴリズムを使うことができるようになっています。ちなみに、Stable Diffusionで推奨されているスケジューラアルゴリズムは、「PNDM、DDIM、K-LMS」の3つになります。
③ Text-encoder
Stable Diffusionでは「文章で指示」を出せますが、文章はそのままでは扱えないため、文章をベクトル化(分散表現にエンコード)する必要があります。
図右側の「Conditioning」領域の部分になりますが、ここでText-encoderが使われています。
Stable Diffusionでは、既に学習済みのCLIPのテキストエンコーダ(CLIPTextModel)をそのまま使用しているようです。(GoogleのImagenにインスパイアされているらしい)
🧿Stable Diffusionで使われているデータセット
Stable Diffusionの学習には、LAION-5Bのサブセットである「LAION-Aesthetics」が利用されています。これは、LAION-5Bのデータセットから、独自の「美学スコア」で選抜したデータセットになります。
参考までに、LAION-5B(Aestheticsではない)に含まれているデータセットは、以下のサイトで簡単にプレビューが可能です。
https://rom1504.github.io/clip-retrieval
🧿実は文章だけじゃ無いStable Diffusion
もう一度 Latent Diffusion Modelの概要図を詳しく見ると分かるのですが、Conditioning領域からU-Netに対して伸びている線は、Textだけではなく、Semantic MapやImagesなど「複数の要素が含まれている」ことが分かると思います。 Stable Diffusionといえば、「文章から画像」、最近では「画像から画像」というイメージが強いかもしれませんが、実は「それ以外の情報も普通に渡せる」仕組みになっています。
Stable Diffusionといえば、「文章から画像」、最近では「画像から画像」というイメージが強いかもしれませんが、実は「それ以外の情報も普通に渡せる」仕組みになっています。
そのため、画像の一部分を塗りつぶしたマスク情報を与えて、その部分を補完させる・・・みたいな応用も可能になります。
また、入力した文章も実際には「分散表現」になるため、複数の分散表現のベクトル間をスムーズに移動させながら順次画像を生成すれば、モーフィングみたいな事も可能になるはずです。(実際の分散表現上の位置は、線形的につながるわけではなさそうなので、そんなに単純にはいかないかもしれませんが・・・)
また、U-Netの中間層のデータを抽出して、そこに対して別の処理を加えたり、他の部分と連結させる・・・みたいなこともできそうですね。
🧿まとめ
ということで、最後にStable Diffusionのポイントについてまとめて終わりにしたいと思います。
1. Stable Diffusionは、Latent Diffusion Modelの応用
2. 実画像では無く潜在変数に対してDiffusion Modelを適用した事がポイント
3. 実画像と潜在変数間の変換はVAEを使っている
4. 潜在空間でのノイズ除去にはU-Netを使っている
5. U-Netにはcross-attentionが入っていて、ここで色々制御できる
6. cross-attentionへの入力は文章(分散表現)以外でも指定できる
なお、これらの内容は個人的に調査してまとめたものなので、もし間違っている点などあれば、そっと教えていただけると嬉しいです!