




2023年5月12日のAI EXPOで、画像系の生成AIである「Stable Diffusionの進化」についてプレゼンさせていただきました。
発表時のプレゼン資料と簡単な解説について、ここで共有したいと思います。なお、時間の都合でEXPOでは省略していたいくつかの技術(CutoffやGLIGENなど)についても、スライドを追加しています!
📌プレゼン資料(PDFファイル)
完全版のプレゼンファイルは、下記URLからダウンロードできます!
他の人たちへの紹介や資料連携など、オリジナルファイルの状態でしたら自由に利用していただければと思います!
📌プレゼン解説
プレゼン資料自体には説明をあまり付けていない(発表時に口頭で説明する前提の資料)ので、簡単に各スライドに対する説明も載せておきたいと思います。 今回は、2022年7月に登場した「Stable Diffusionの進化」について分かりやすくお伝えしたいと思います。生成AIでは「ChatGPT」のようなLLMが流行っていますが、今回取り上げるのは「画像系の生成AI」になります。
今回は、2022年7月に登場した「Stable Diffusionの進化」について分かりやすくお伝えしたいと思います。生成AIでは「ChatGPT」のようなLLMが流行っていますが、今回取り上げるのは「画像系の生成AI」になります。 簡単な自己紹介です。会社ではAIに関するプロジェクトなどに携わっています。
簡単な自己紹介です。会社ではAIに関するプロジェクトなどに携わっています。
CDLEでは、色々なAIモデルの情報を分かりやすく発信していく「AI Repository」グループのリーダーも務めさせていただいています。
🌐AI Repository - https://cdle.jp/contents/1d268086c03f  Stable Diffusionはこんな感じの画像を生成できるAIです。(2022年7月時点)
Stable Diffusionはこんな感じの画像を生成できるAIです。(2022年7月時点) Stable Diffusionの登場で、色々な画像を誰でも簡単に生成できるようになりました。
Stable Diffusionの登場で、色々な画像を誰でも簡単に生成できるようになりました。 画像を生成できるAIは複数存在しますが、Stable Diffusionは「オープンソース」で誰でも無料で利用できる点がポイントになります。
画像を生成できるAIは複数存在しますが、Stable Diffusionは「オープンソース」で誰でも無料で利用できる点がポイントになります。
MidjourneyやDALL・E2などのサービスも有名ですが、これらは特定ベンダー内に閉じた形で開発されており、誰でも無料で自由に触ることはできません。 Stable Diffusion(略してSD)の基本的な使い方として、生成したい画像の説明文(プロンプト)を入力して画像を生成する方法があります。(txt2imgとも呼ばれる)
Stable Diffusion(略してSD)の基本的な使い方として、生成したい画像の説明文(プロンプト)を入力して画像を生成する方法があります。(txt2imgとも呼ばれる)
例えば「summer beach, ocean, sunset」というプロンプトで、上記のような画像を生成できます。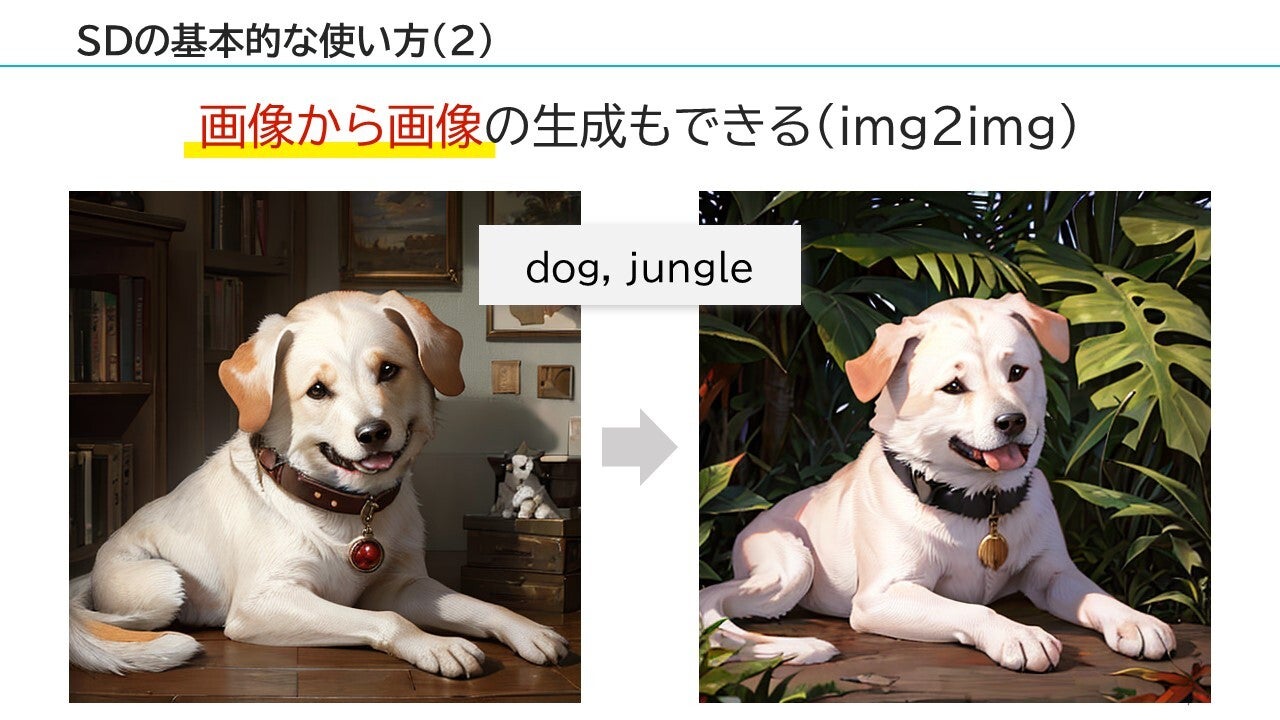 また、「画像から画像」する事も可能です。(img2imgと呼ばれます)
また、「画像から画像」する事も可能です。(img2imgと呼ばれます)
例えば、左の犬の写真をベースに「dog, jungle」というプロンプトの指示で、背景画像だけをジャングルの画像のように変更することも可能です。 それでは、Stable Diffusionの簡単な説明はこのくらいにして、早速「Stable Diffusionの進化」について見ていきましょう。
それでは、Stable Diffusionの簡単な説明はこのくらいにして、早速「Stable Diffusionの進化」について見ていきましょう。
Stable Diffusionが2022年7月に登場してから、まだ10ヶ月くらいしか経っていませんが、この間に大きく進化しているので、それらの一部を少しでも感じていただければと思います! まずは、色々な「モデル」が登場してきました。
まずは、色々な「モデル」が登場してきました。
アニメ調、芸術的なアート調、写真のようなリアルな画像・・・など、生成したい画像の内容に合わせて大量のモデルが登場しています。
上記は全て「a old man」というプロンプトしか指定していませんが、利用するモデルによって生成される画像が大きく違ってきています。 続いて「含めたくない要素」を意図的に省くための、「ネガティブプロンプト」や「テキスト反転(Text Inversion)」という技術が登場しました。
続いて「含めたくない要素」を意図的に省くための、「ネガティブプロンプト」や「テキスト反転(Text Inversion)」という技術が登場しました。
例えば、上記左側の画像で「窓を表示したくない・・・」という場合は、ネガティブプロンプトに "window" を指定すれば、「windowを排除」できるようになります。
他にも「低品質の画像や、手足が解剖学的にあり得ない感じの画像を省く」ためにも、このネガティブプロンプトが利用されます。("low quality" や "bad anatomy" などのネガティブプロンプトが良く利用されます)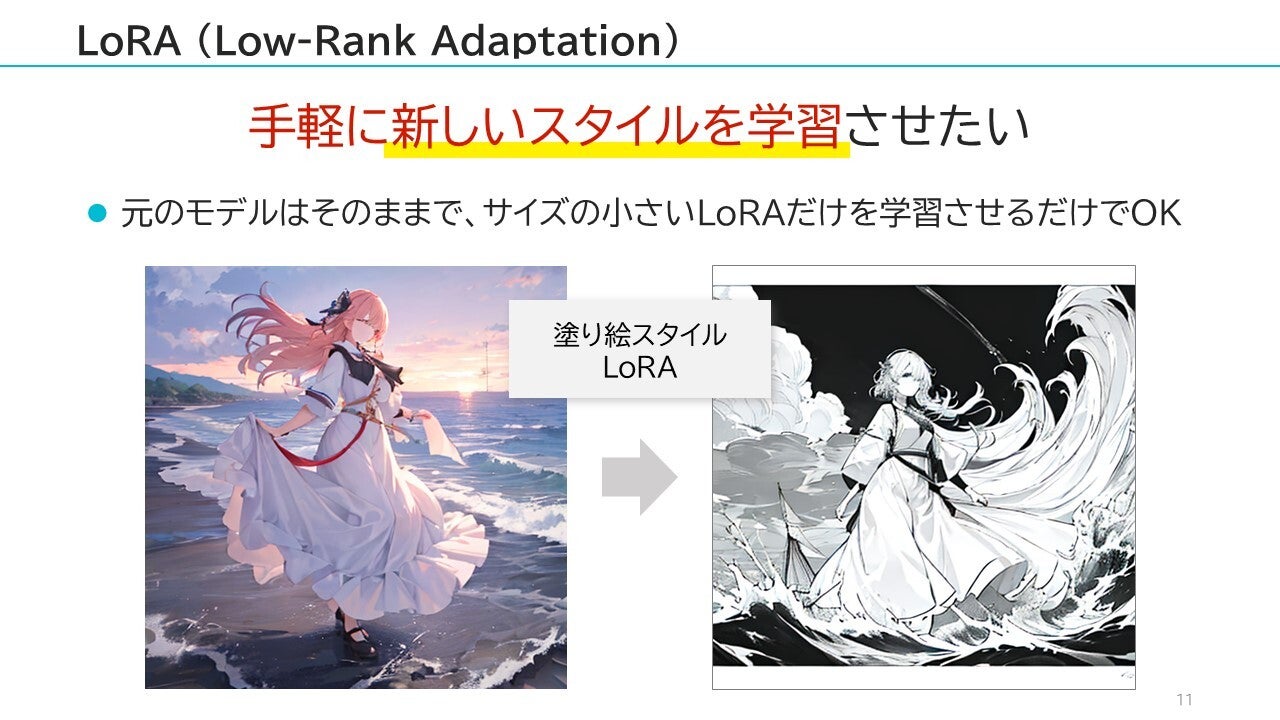 独自の画像をモデルに学習させたい場合、Stable Diffusionのモデルに再学習させる必要がありますが、元のモデル自体の再学習には「多くの計算コスト(や時間)」が必要になります。そこで登場したのが、LoRAという「元のモデルとは別の、サイズの小さなモデルだけをトレーニングする」手法です。LoRA自体はモデルサイズが小さいので、学習に必要なコストも少なくなり、誰でも簡単にモデルをチューニングできるようになりました。
独自の画像をモデルに学習させたい場合、Stable Diffusionのモデルに再学習させる必要がありますが、元のモデル自体の再学習には「多くの計算コスト(や時間)」が必要になります。そこで登場したのが、LoRAという「元のモデルとは別の、サイズの小さなモデルだけをトレーニングする」手法です。LoRA自体はモデルサイズが小さいので、学習に必要なコストも少なくなり、誰でも簡単にモデルをチューニングできるようになりました。
上記の例では「塗り絵スタイルのLoRA」を適用することで、簡単に塗り絵スタイルの画像を生成できています。
なお、このLoRAの考え方は、最近はやっているLLM(大規模言語モデル)でも利用されています。LLMはStable Diffusionよりも更にモデルサイズが巨大なことも多く、モデル自体の再学習コストが大きくなりやすいため、この部分にLoRAする研究も進んでいます。 元画像をベースに、簡単にスタイルを変更できる「Instruct pix2pix」のような技術も登場しています。
元画像をベースに、簡単にスタイルを変更できる「Instruct pix2pix」のような技術も登場しています。
左上のoriginalが元画像になりますが、ここに「"sunset", "ice world", "dark forest"」のようなスタイルを適用するだけで「元の画像を可能な限り残しつつ、スタイルを変更」できるようになります。 Stable Diffusionは、GPUのVRAMサイズなどの都合もあり、パノラマ画像や極端に大きなサイズの画像を生成できない・・・という課題がありました。そこで登場したのが「Tiled Diffusion」や「Tiled VAE」や「Upscaler」になります。
Stable Diffusionは、GPUのVRAMサイズなどの都合もあり、パノラマ画像や極端に大きなサイズの画像を生成できない・・・という課題がありました。そこで登場したのが「Tiled Diffusion」や「Tiled VAE」や「Upscaler」になります。
これらにより、VRAMのサイズが少ない場合であっても「パノラマ画像」や「かなり大きなサイズの画像」を生成できるようになりました。 Stable Diffusionは、プロンプトなどで生成画像の指示をする・・・という点から、1つの画像に対して「複数の要素を厳密に描き分ける」ということが非常に困難でした。
Stable Diffusionは、プロンプトなどで生成画像の指示をする・・・という点から、1つの画像に対して「複数の要素を厳密に描き分ける」ということが非常に困難でした。
例えば「white cat with blue eyes, black cat with yellow eyes」というようなプロンプトを指定したとしても、Stable Diffusionは「どの色が何に対して指定してあるか厳密に理解できない」ため、全てが混在したような画像が生成されることが多くなります。
そこで、「Two shot diffusion」や「Latent Couple」という方法が登場し、「画像の領域ごとに異なるプロンプト」を指定できるようになりました。
これにより、複数の要素を「明確に描き分ける」ことが可能になり、これを利用する事で「左側が冬、右側が夏」とか、「左側が夜、右側が昼」のような通常はあり得ないアート的な作品も生成できるようになります。
なお、それぞれの境界も「滑らかで自然な感じで」繋がるような工夫がされています。 そして、最も衝撃的だったのが「ControlNet」の登場です。(類似する物として、T2I-Adapterも登場しています)
そして、最も衝撃的だったのが「ControlNet」の登場です。(類似する物として、T2I-Adapterも登場しています)
ControlNetが登場するまで、ポーズや表情などは「全てプロンプトで指示」する必要があり、プロンプトだけでは、なかなか思った通りのポーズが再現できない・・・というのが万人共通の悩みでした。(思った通りの画像が生成されるまで、何十~何百枚と画像を生成し続ける・・・というガチャ感が強かった)
ControlNetを使うと、生成したいポーズなどを「厳密に制御」することが可能になります。つまり、プロンプトで指示すること無く「こんな感じのポーズで、表情はこうしてね・・・」という指定が1発でできるようになります!!!!!
なお、この「骨格ポーズ」などは、Webカメラの画像から簡単に生成できるので、「自分自身で好きなポーズを簡単に指定」できるようになります。 上記では「骨格によるポーズ指定」でしたが、ControlNetは他にも色々な方法で生成画像の制御が行えるようになっています。(輪郭線や落書き、ポーズ、深度マップ、セグメンテーションマップ、法線マップ、色情報・・・などなど)
上記では「骨格によるポーズ指定」でしたが、ControlNetは他にも色々な方法で生成画像の制御が行えるようになっています。(輪郭線や落書き、ポーズ、深度マップ、セグメンテーションマップ、法線マップ、色情報・・・などなど)
色々な方法での制御が可能なため、例えば次のような事も簡単に行えます。
・既に存在する写真と同じ構図やポーズで、新しい画像を生成する
・適当な白黒の落書きから、かなり高品質な画像を生成する(絵心が無くてもOK)
・線画に対して自動で着色する
・etc...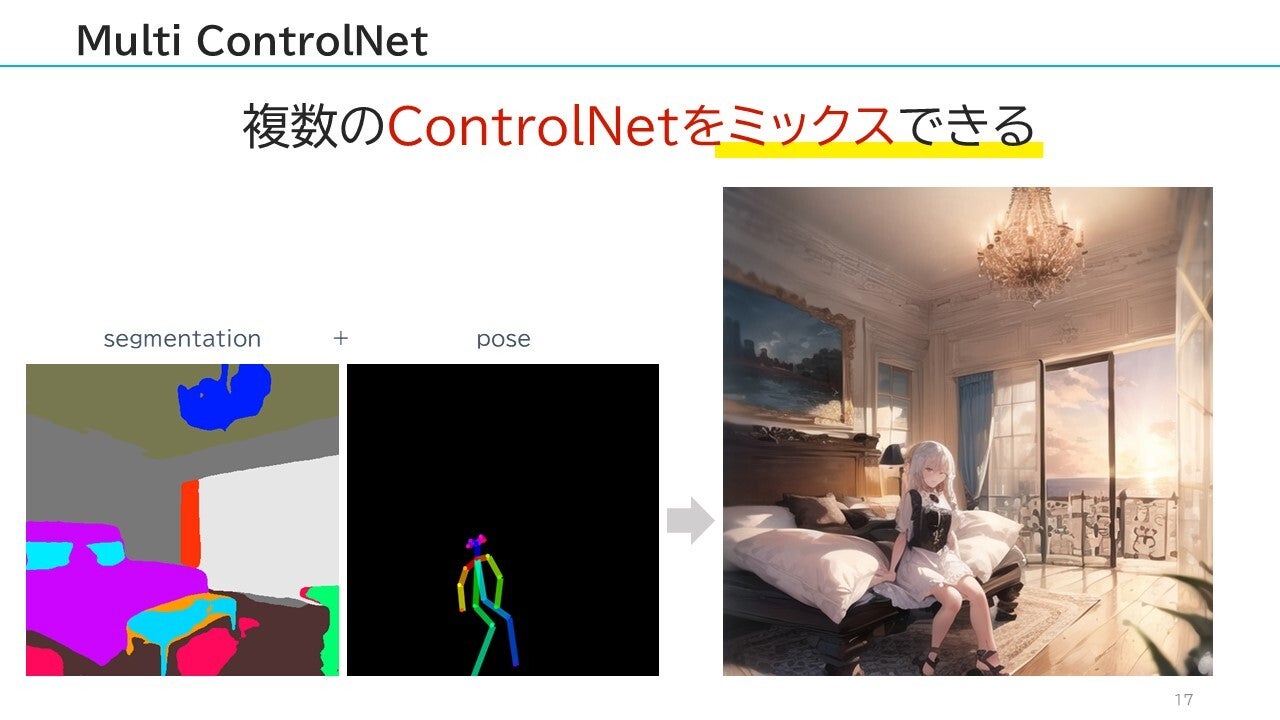 また、ControlNetで「複数の要素をミックス」する「Multi ControlNet」という方法も登場しました。
また、ControlNetで「複数の要素をミックス」する「Multi ControlNet」という方法も登場しました。
Multi ControlNetを使えば、上記のように「背景はセグメンテーションで指定」して「人物は骨格ポーズ」で制御・・・というような事が簡単に実現できます。 ControlNetに関連して、「Guess mode」機能も登場しています。
ControlNetに関連して、「Guess mode」機能も登場しています。
通常であれば、ControlNetを利用する場合でも、生成する画像全体の大まかな内容(例えば、"1girl, living room"など)をプロンプトで指定するのですが、Guess modeは「プロンプトを全く指定しなくてもOK」・・・というモードです。
プロンプトを全く入力していない場合、通常であれば「どのような画像を生成すれば良いのか明確な指示が無い」ため、上記中央の画像のような、少し崩れた画像になりがちです。(これはこれで、アート的に味のある画像ではありますが・・・)
ここで、Guess modeを利用すれば、プロンプトを全く入力していなくても、上記右画像のように綺麗な画像を生成できるようになります。 Stable Diffusionは「プロンプト中のキーワードが、どの単語に対して対応付いているか十分には理解できていない」ため、プロンプト中に複数の色が含まれていると「他の部分に色移り」することがあります。
Stable Diffusionは「プロンプト中のキーワードが、どの単語に対して対応付いているか十分には理解できていない」ため、プロンプト中に複数の色が含まれていると「他の部分に色移り」することがあります。
例えば「yellow hair, white shirt, green tie, red coat」というプロンプトの場合、Stable Diffusionでは何をどの色にすれば良いのか混乱して、「green tieと指定しているはずが、red coatの "red" に影響を受けてしまう」ような事が普通に発生します。
このような色移りを「低減(完全に無くせるわけではありません)」するため、Cutoffという手法が登場しています。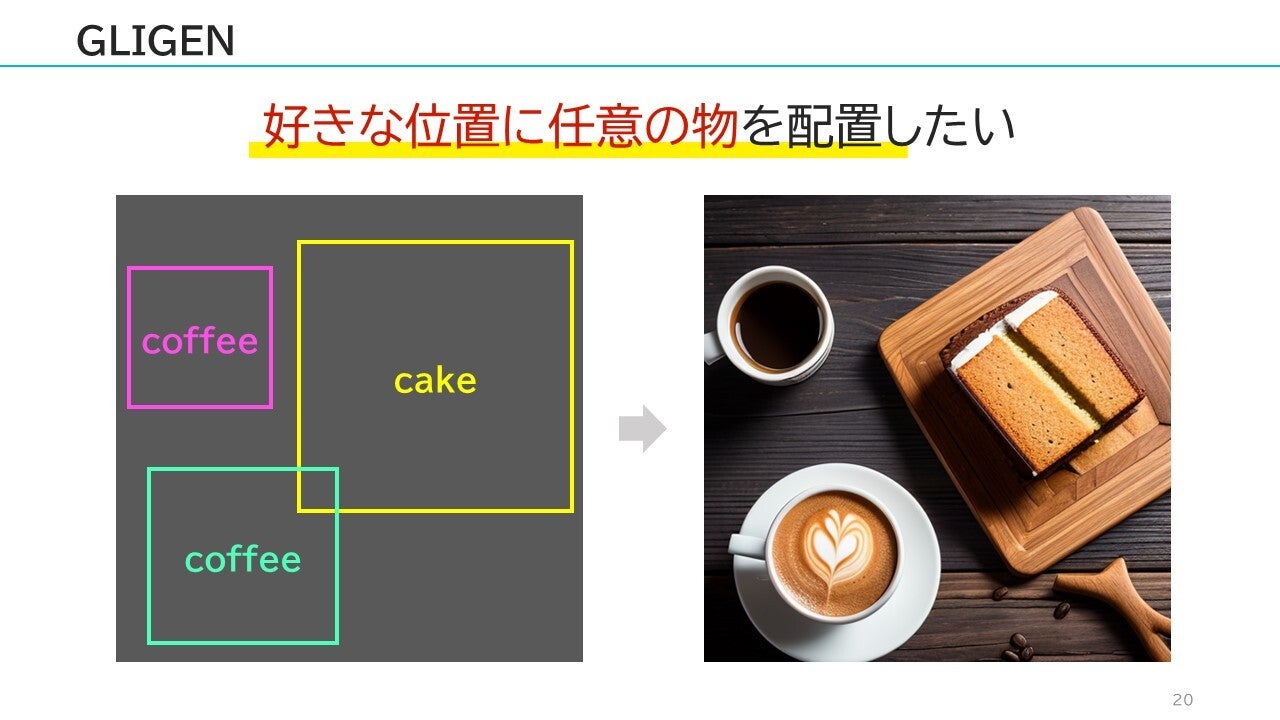 ControlNetに少し似ている部分もありますが、「好きな場所に任意の物体を配置」したいケースもあると思います。(例えば、この位置にコーヒー、この位置にケーキ・・・など)
ControlNetに少し似ている部分もありますが、「好きな場所に任意の物体を配置」したいケースもあると思います。(例えば、この位置にコーヒー、この位置にケーキ・・・など)
このようなニーズに対しては、GLIGENという手法で対応できるようになります。 他にも色々な技術が存在していて、現在進行形で次々と進化し続けています。
他にも色々な技術が存在していて、現在進行形で次々と進化し続けています。
特に現時点では、ControlNetを活用した動画生成の話題が多いように思います。単純にControlNetを使って動画を生成しても「フレーム間の整合性が取れずに、似たような画像を寄せ集めたパラパラ漫画風」の動画にしかならないのですが、現在は「フレーム間の整合性を保った状態で動画を生成する」ような方法も研究されています。 このように、登場してすぐに大きく発展した背景には「オープンソースコミュニティ」の存在があります。誰でも自由に色々触れるからこそ、多方面からさまざまなアイデアが登場して、短期間で大幅に進化してきました。(もともと、Stable Diffusionよりも性能の良かった画像生成AIですら、自由に使えないという理由で、多くの人が興味を示さなくなりました)
このように、登場してすぐに大きく発展した背景には「オープンソースコミュニティ」の存在があります。誰でも自由に色々触れるからこそ、多方面からさまざまなアイデアが登場して、短期間で大幅に進化してきました。(もともと、Stable Diffusionよりも性能の良かった画像生成AIですら、自由に使えないという理由で、多くの人が興味を示さなくなりました)
・・・実は、同じような流れが、現在のLLM(大規模言語モデル)でも言えるかもしれません。現在はOpenAIのChatGPTなどが話題ですが、ChatGPTなどは「クローズド」な世界で開発されていて、誰でも触れる状態にはありません。
そんな中で、まだ精度は十分ではないものの、オープンなLLMもいくつか登場してきています。これらもStable Diffusionと同じような流れで、色々な人が触り「パラメータ数が少ないにもかかわらず、ChatGPTに匹敵するほどの性能まで」あっという間に進化しました。
画像系に限らず、今後の生成AIは、まだまだ熱くなりそうですね!!