




最近ではCopilot+ PC規格に対応したPCをお持ちの方も増えているかと思います。
Copilot+ PCとは40 TOPS以上の処理能力を持つNPU(Neural Processing Unit : ニューラル処理ユニット)を搭載した、AI特化型の次世代Windows 11 PCのことです。
Copilot+ PCではRecallとかライブキャプションなどの機能が利用できるのですが、これらの機能をあまり利用していない場合は持ち腐れになってしまいます。
自分のPCにもNPUが入っているのですが全然使っていないので、何かしらNPUを動かしてみたいと思いローカルLLMを使ってみることにしました。
NPUでローカルLLMを動かすには?
LLMを動かすソフトウェアが必要です。いくつか選択肢があり、たぶん一番手っ取り早いのはLM Studioですが、今回はMicrosoftが出しているFoundry Localを利用することにしました。
Foundry Localのインストール方法
コマンド1個打つだけです。簡単です。詳細はこちら。
NPU対応モデルを探す
Foundry LocalのWebページで探せます。
Execution DeviceでNPUを選択すると、NPUに対応しているモデルが出てきます。
QwenやPhiなどが選べます。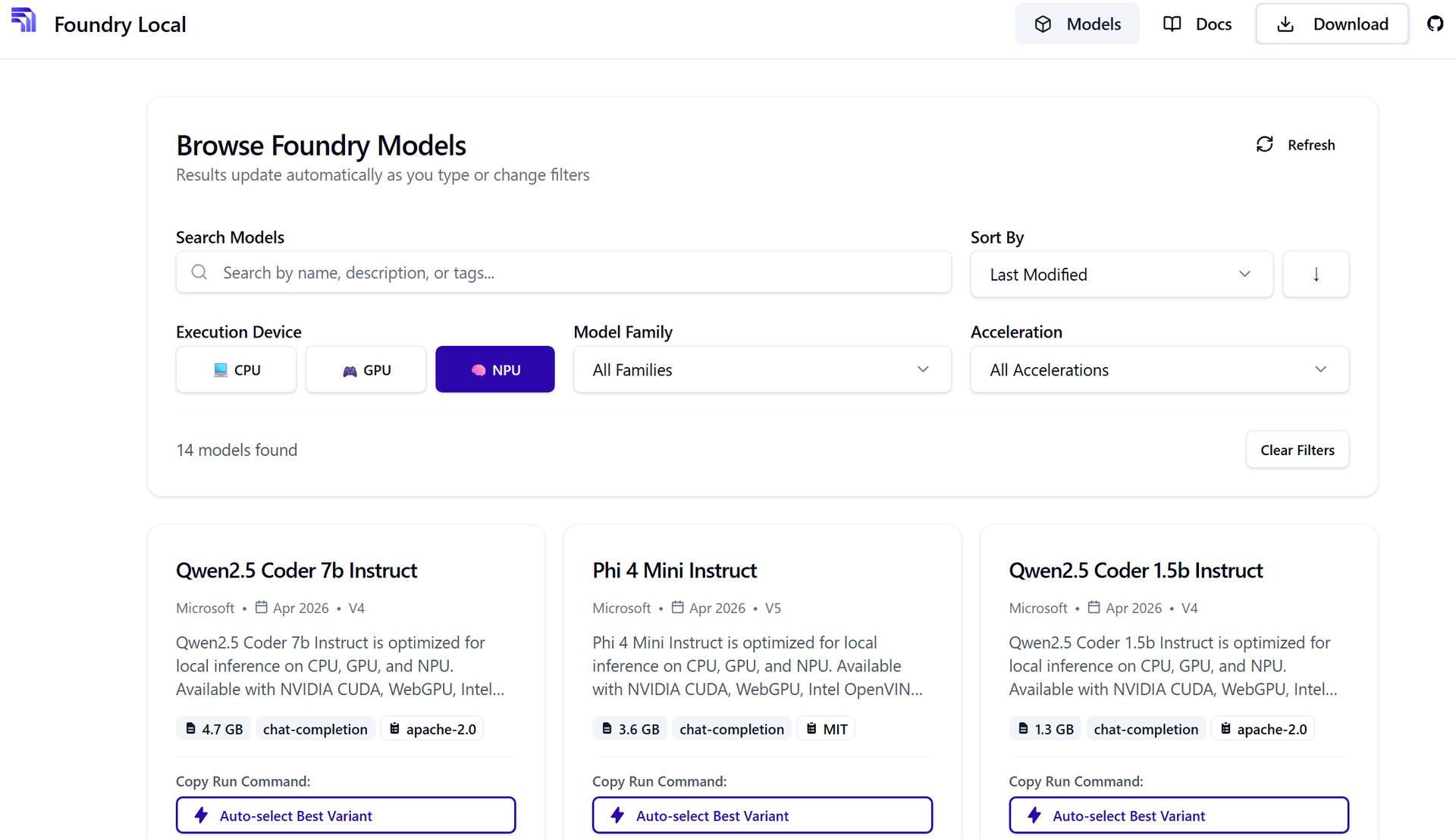
NPUモデルを動かす
これもコマンド1個打つだけです。たとえばPhi 4 Miniの場合:
foundry model run phi-4-mini
そうすると自動的に最適なものを勝手に選んでダウンロードしてくれます。
NPUが入っている場合は、NPU用のものを入れてくれると思います。
無事ダウンロードが終わるとインタラクティブモードになるので、あとは普通にチャットするだけです。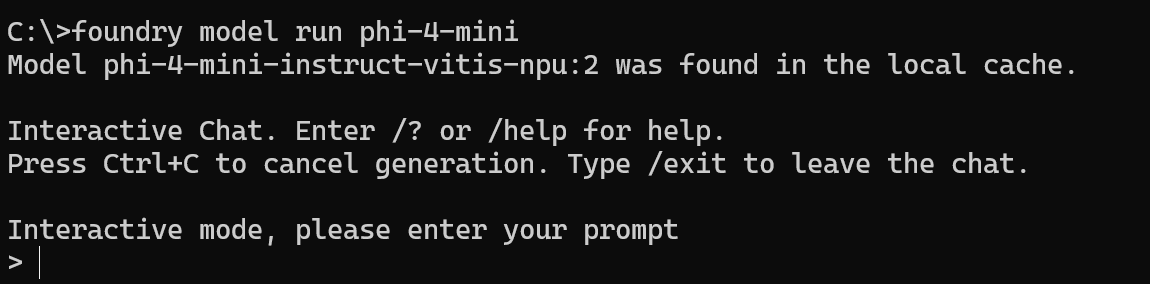
何かプロンプトを打つとAIモデルが実行されます。実行中、タスクマネージャでNPUの項目を開くとNPUが稼働していることがわかります!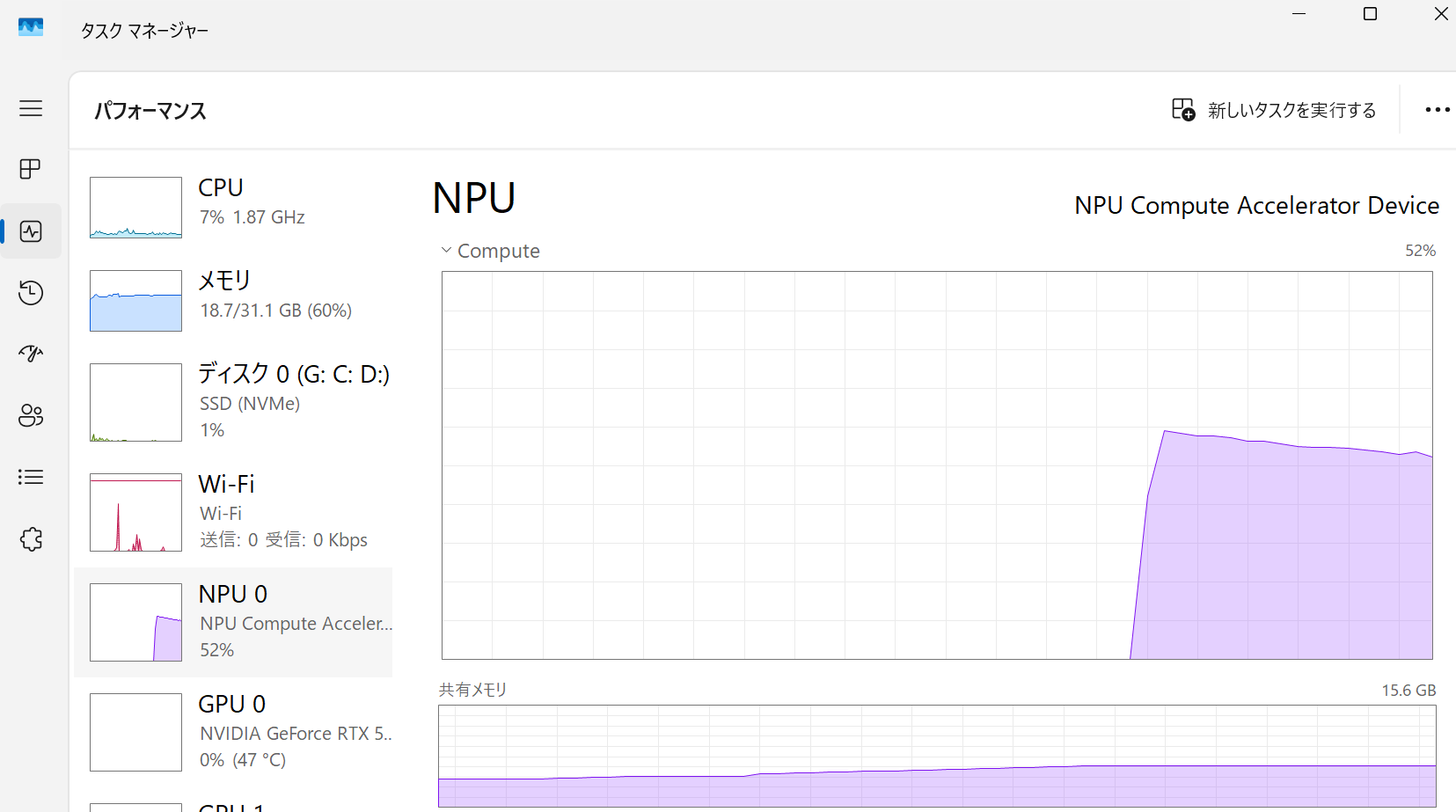
今回使用しているNPUは、NPUとしては高性能なほうなのですが、Phi 4 Miniのような小さなモデルでも出力はゆっくりです。以下のような内容でも出力に20秒ぐらいかかります。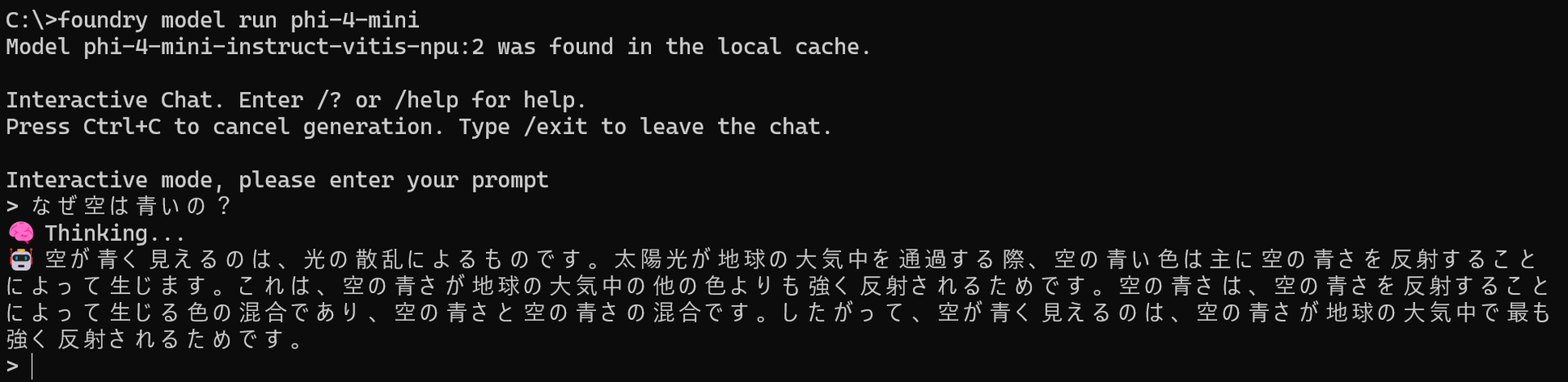 同じ内容をGemini(高速モード)に入れると7-8秒でもっと詳しい回答が返ってくることを考えると、NPU+ローカルLLMでクラウドAIモデルのような快適さを求めるのは難しいです。
同じ内容をGemini(高速モード)に入れると7-8秒でもっと詳しい回答が返ってくることを考えると、NPU+ローカルLLMでクラウドAIモデルのような快適さを求めるのは難しいです。
とはいえ、利用料金ゼロで全部ローカルで処理できる利点があるので、活用方法はいろいろありそうに思います。