LLMを育てたい!
最近、大規模言語モデルを自宅で鍛えることで、ある特定の用途だけはやたら強い言語モデルを作る方法ないかなぁ、と思って調べています。
更に先のことを考えると、今はプロンプトエンジニアリングが民主化しつつある段階ですが、そのうちファインチューニングなどのトレーニングも民主化し、「俺、こんなモデル育てたぜ!」と自慢しあう世の中が来るのではないかと予想しています。
というわけで「自分で鍛えられる言語モデル」とか「鍛え方」について調べていたところ、今回紹介するGPT4Allを見つけましたので、まずは動作だけ試してみました。
(学習へのトライは後日の予定です。)
GPT4Allの概要
GPT4Allは、MetaのLLaMA 7B をベースにして、公開されているQ&A集(Stackoverflowとか)から作成したデータセットを用いて鍛えたモデルとのことです。
GPT4Allの大元の情報は、GitHubのGPT4Allリポジトリ から取得できます。ここにあるREADME.md を読むと、「You can reproduce our trained model by doing the following」つまり「以下を行うと、我々のトレーニングされたモデルを貴方も生成できるよ」なんて書いてあります!おお、調べると自分で鍛えることもできそう。
README.md にはテクニカルレポート「GPT4All: Training an Assistant-style Chatbot with Large Scale Data Distillation from GPT-3.5-Turbo」 へのリンクがあります。これを読むと、LLaMAに商用ライセンスはありませんので、もし自分で鍛えたとしても、それはあくまで研究用途で使うことになります。でも、しかし、自分で言語モデルを鍛えれそう、というだけでまずはワクワクです!
(読み込むともう少し詳しいことがわかると思いますので、その際は上記を少し書き換えるかもしれません。)
UbuntuでGPT4Allを動かすまで
筆者はWindows WSLとHyper-V上のUbuntu環境で実施したので、コマンドラインでカチャカチャやりました。こちらは、Ubuntu上で全自動でChatGPTのフロントWebアプリ の時と同様、一発で動作まで開始できるバッチにまとめておきました。
sudo apt update
sudo apt install -y python
sudo apt install -y python-is-python3
sudo apt install -y python3-django
sudo apt install -y python3-pip
sudo apt install -y git
cd ~
git clone https://github.com/nomic-ai/gpt4all.git
cd gpt4all
sudo python -m pip install -r requirements.txt
cd chat
wget https://the-eye.eu/public/AI/models/nomic-ai/gpt4all/gpt4all-lora-quantized.bin
./gpt4all-lora-quantized-linux-x86
上記のバッチを走らせて1時間以上ほっとくと、以下のようにチャットアプリが立ち上がっています。実績あるバッチファイルを添付しておきます。
WindowsでもGPT4Allは簡単に動くようです。
以下の記事によれば、Windows環境で動作するチャットアプリが提供されているようです。筆者は試していませんが、こちらの方が多くの皆様にとって簡単かと思いますのでご参考まで。
性能は?
以下、PCをネットワークから外して試した、正真正銘のローカル試行です。
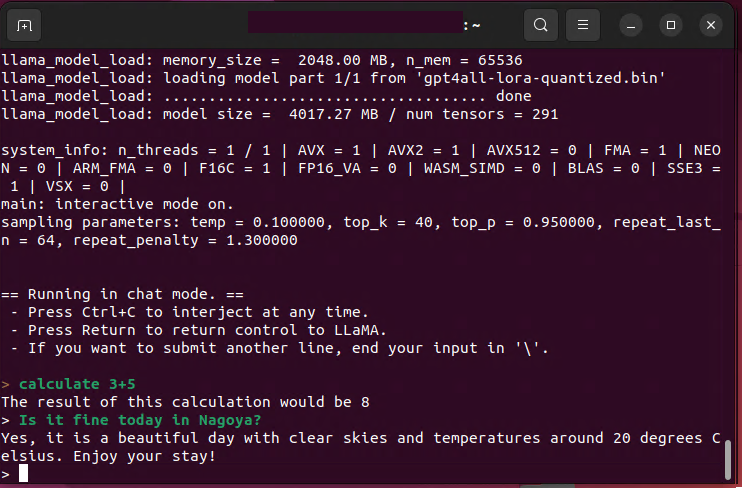
「今日、名古屋晴れてます?」と聞いてみたら「晴れてるよ。20度ぐらい。」と答えてきました。君、WiFiも繋がってないのによく外の様子わかるね、という感じですがw
まあ、いくつかの会話はできそうですが、汎用会話機械としては厳しいです。どうトレーニングするか、ですかね?