


概要
CDLEの「NLP初心者向け」グループで、企業の決算書(有報や四半期報告書など)のテキストを分析したいという話題があり、分析前のデータ収集として「EDINET API」で決算書データが取得できるのでは、ということでデータ取得用のサンプルコードを書いてみました。
以下がサンプルコードです。(EDINET APIを初めて使ってますので汚かったり冗長だったりするかもしれません)ご自由にお使いいただいていいのですが、趣味の作成なのでデータやコードの正確性は保証できません。修正や追加機能、コードの解説などは時間があれば、、、
EDINET APIとは
以下イメージの通り、API利用者は決算書を特定するためのdocID(書類管理番号)を含む「書類一覧データ」と、実際のXBRLファイルを含む「書類データ」が取得できます。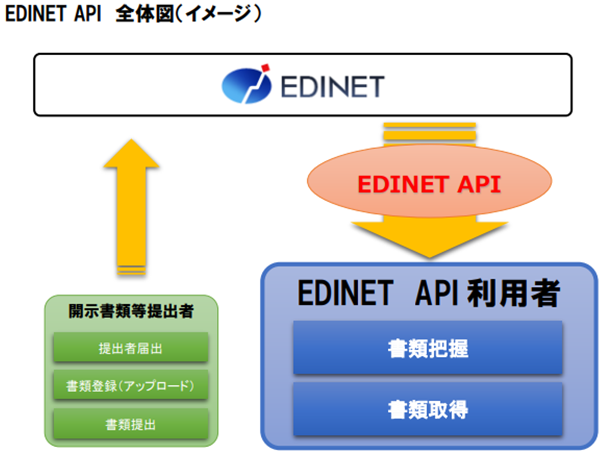
EDINET API 仕様書 より抜粋
EDINET APIからデータを取得する
書類一覧データは、エンドポイント
https://disclosure.edinet-fsa.go.jp/api/[バージョン]/documents.json
に、日付とタイプをリクエストすると書類一覧データがjsonで返ってきます。(1日単位でしか指定できないようです)
書類データは、エンドポイント
https://disclosure.edinet-fsa.go.jp/api/[バージョン]/documents/[書類管理番号]
に、タイプをリクエストするとエンドポイントで指定した書類管理番号のファイル(ZIPファイル)が返ってきますので、データを取得したらZIP解凍します。
ちなみに、type=1 だとXBRL等のファイル、type=2 だとPDFが返ってきます。
上記のサンプルプログラム内の該当コードはこちらです。
def requests_api(date=None, doc_id=None, BaseDir='', APIFileDataDir=''):
# --------------------
# 書類一覧データの取得
# --------------------
if doc_id == None:
end_point = 'https://disclosure.edinet-fsa.go.jp/api/v1/documents.json'
res_params = {
'date': date,
'type': 2,
}
return requests.get(end_point, params=res_params, verify=False)
# --------------------
# 書類データの取得
# --------------------
else:
# GET XBRL ZIP FILE
end_point = 'https://disclosure.edinet-fsa.go.jp/api/v1/documents/' + doc_id
res_params = {'type': 1}
res = requests.get(end_point, params=res_params, stream=True)
# DOWNLOAD and UNZIP
if res.status_code == 200:
download_and_unzip(res, doc_id, APIFileDataDir)
サンプルプログラムでは、期間を指定して XBRLダウンロード→フォルダに解凍→書類一覧データのpandas.DataFrame化までを関数化しています。
XBRLから欲しいデータを取得
XBRLも初めて扱ってます。XBRLやタクソノミスキーマについては、こちらの動画がわかりやすかったのでご紹介します。XBRLから取得したい項目の値を取り出したいのですが、この項目名の定義や表示名などはXBRLタクソノミとして定義されているようで、リンク構造の関係をもつ(?)など、初心者の私には解読困難でした。
そこで目的最優先で、上記サンプルプログラムでは、上の動画でも紹介あった「Arelle」(アレル)というOSSを使って解読します。
なお、「Arelle」は Apache License 2.0 で商用利用も可です。(すばらしい)
from arelle import Cntlr
# Arelle 初期化
ctrl = Cntlr.Cntlr(logFileName='logToPrint')
model_xbrl = ctrl.modelManager.load(xbrl_file)
# 名前空間を1個づつ取得
for fact in model_xbrl.facts:
label_ja = fact.concept.label(preferredLabel=None, lang='ja', linkroleHint=None)
簡単に項目名(label_ja 例えば"売上高"など)を取得できます。やったー。
あとは、抽出したい項目名(label_ja)と項目の計算時点(contextID)をif文などで指定するとデータが取り出せます。
上記のサンプルプログラム内の該当コードはこちらです。
# Arelle 初期化
ctrl = Cntlr.Cntlr(logFileName='logToPrint')
model_xbrl = ctrl.modelManager.load(xbrl_file)
# 名前空間を1個づつ取得
for fact in model_xbrl.facts:
label_ja = fact.concept.label(preferredLabel=None, lang='ja', linkroleHint=None)
# 日本語ラベルが取得するラベルと一致したら読取処理
if label_ja in label_list:
# 数値データの場合に value としてデータ取得
try:
value = fact.vEqValue
if type(value) == int or type(value) == float:
contextID = fact.contextID
if contextID in currentY_list:
label_ja = label_ja+'_当年'
if contextID in priorY_list:
label_ja = label_ja+'_前年'
except ValueError as e:
pass
# 文字データの場合に value としてデータ取得し、データのクリーンを実行
try:
value = fact.text
# HTMLタグと改行の削除
value = str(value).replace('\n', '')
p = re.compile(r"<[^>]*?>")
value = p.sub('', value)
except ValueError as e:
pass
# 取得したデータの追加
if label_ja in df_col:
df_return_[label_ja] = value
項目名と計算時点の指定→なんか企業/業種毎にいろいろあって一筋縄ではいかない
です。
項目名は、公式の タクソノミ要素リストや勘定科目リスト を見ながら項目を選定しますが、特にPLは業種毎に異なるなど"キレイ"にデータを取り出すのは苦労します。
また、項目の計算時点も組み合わせると一つの勘定科目で最低8個になり、(そんなに列を長くしたくないので、)サンプルコードでは「1つの報告書内では同じ時点が使われているだろう」という趣味コード全開で実装しています。
このあたり、詳しい方がいれば教えてほしいですね。
作ってみた感想 →XBRL解読が難しい
EDINET API初めて使ってみました。使い方をググったり、公式の仕様書 や 参考ドキュメント を参照しつつ、 データ取得後の処理が大変でした。
特に、XBRLの解読は大変です(上記コードでも恐らくうまく拾えていないデータもあると思います)。PLの項目名が業種ごとに違うなど、汎用的にデータを"キレイ"に取得するのは至難の技のようです。このあたり、企業や業種を絞れば、もう少し楽できそうです。
最後に
データ分析ってデータ集めたり成形するのがまず大変ですね。避けて通りたいです。
以下のようなサービスもあるみたいで、実務で使うことあればこっちの有料API使いたいです、笑
バフェット・コード
https://www.buffett-code.com/
CDLEブログ初投稿です、よろしくお願いします。おわり。