




ChatGPT Nightというイベントで「ChatGPT(API)とカメラを使って遊ぶ」という発表をさせていただきました。また、生成AI EXPO in 東海というイベントでは「AIモンスター人相占い」を公開したのですが、これらのコンテンツの仕組みについて、まだ詳しく記事にできていなかったため、遅くなりましたが、ご説明したいと思います。
📹 AIとのコミュニケーションで感じる壁 🙋
私はイベント会場等で、AIとのコミュニケーションを行う体験したり、自ら展示も行いましたが…下記のような問題と感想を待ちました。
操作性の複雑さ
キーボードやマウスで操作するシステムでは、いちいち入力やクリックが煩わしく、思うように対話が進まない。
音声入力の心理的ハードル
周囲の目が気になったり、何を話せばいいのか迷ってしまい、挨拶のみで、その後、結局対話が始まらない。
これらの体験を通じ、「AIと人間が自然にコミュニケーションをとるには何が必要なのか?」という疑問が浮かびました。
📹 コミュニケーションの本質を考える 🙋
この疑問を掘り下げるために、まず「コミュニケーションとは何か?」を考える必要があります。ここで参考にしたのが、心理学者アルバート・メラビアンの研究となります。
著書である『Silent Messages』(1971年)は、コミュニケーションにおける視覚・聴覚・言語の割合に関する研究結果が記述されています。メラビアンによれば、相手に与える印象は次のように構成されているとのことです。
視覚情報(表情やジェスチャー):55%
聴覚情報(声のトーンや速さ):38%
言語情報(話の内容):7%
この「メラビアンの法則」は、特に初対面のような状況で重要とされています。つまり、人間のコミュニケーションにおいて、言葉そのものよりも視覚的要素がいかに大きな影響を持つかを示しているのです。
📹 コミュニケーションを拡張するための視覚情報の活用 🙋
この視覚情報をAIとのやりとりに取り入れることで、よりスムーズで自然なコミュニケーションが可能になります。たとえば、カメラを活用して次のようなことを実現することが考えられます。
表情の認識
AIが人間の表情をリアルタイムで認識し、適切な反応を返すことで、感情的なつながりを構築します。
姿勢や動きの検出
身振りや体の動きから意図を読み取り、直感的な操作を可能にします。
ただし、「視覚情報を取り入れる」と言っても、専門的な知識や複雑なプログラミングが必要になるのでは…という懸念があるのではないでしょうか?
📹 ブラウザのみで「視覚情報を取り入れる」事が出来る!? 🙋
実はWEBブラウザのみで実現可能です!
ただし、HTMLファイルを作成してダブルクリックで動かす…というほど簡単には動きません。Webサーバーというものが必要となります。しかし、これらの構築は、面倒なアプリケーションのインストール作業などは一切不要になります。
まずは、下記のページを参考に構築してください。
【環境構築】
構築出来ましたか?
構築できた方も、出来なかった方も、まずはどのようなことが行えるか?
デモンストレーションページを作成しましたので、ぜひ体験してみて下さい!
📹 デモンストレーションとソースコード 🙋
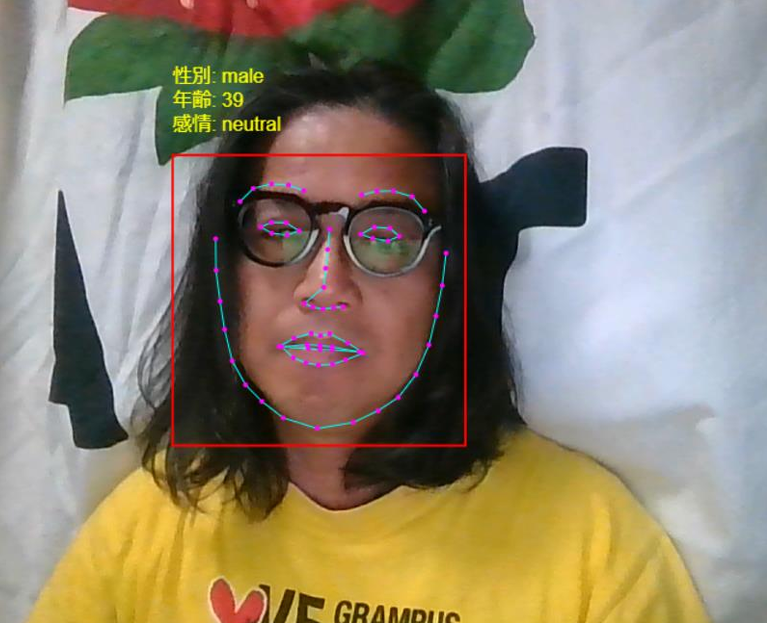
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta charset="viewport" content="width=device-width, initial-scale=1.0">
<title>顔認識、感情、年齢・性別推定</title>
<style>
body {
display: flex;
flex-direction: column;
align-items: center;
justify-content: center;
margin: 0;
height: 100vh;
}
video, canvas {
border: 1px solid black;
margin: 10px;
}
#video {
position: relative;
}
#overlay {
position: absolute;
top: 0;
left: 0;
}
.canvas-container {
position: relative;
width: 720px;
height: 560px;
}
</style>
</head>
<body>
<h1>リアルタイム顔認識、感情、年齢・性別推定</h1>
<div class="canvas-container">
<video id="video" width="720" height="560" autoplay muted></video>
<canvas id="overlay" width="720" height="560"></canvas>
</div>
<br />
<script src="https://unpkg.com/face-api.js@0.22.2/dist/face-api.min.js"></script>
<script>
const video = document.getElementById('video');
const overlay = document.getElementById('overlay');
const overlayContext = overlay.getContext('2d');
const displaySize = { width: video.width, height: video.height };
navigator.mediaDevices.getUserMedia({ video: {} })
.then(stream => {
video.srcObject = stream;
})
.catch(err => {
console.error("カメラへのアクセスに失敗しました:", err);
});
Promise.all([
faceapi.nets.tinyFaceDetector.loadFromUri('models'),
faceapi.nets.faceLandmark68Net.loadFromUri('models'),
faceapi.nets.faceExpressionNet.loadFromUri('models'),
faceapi.nets.ageGenderNet.loadFromUri('models')
]).then(startFaceRecognition)
.catch(err => {
console.error("face-api.jsのモデルのロードに失敗しました:", err);
});
function startFaceRecognition() {
video.addEventListener('play', () => {
faceapi.matchDimensions(overlay, displaySize);
async function detectFaces() {
if (!video.paused && !video.ended) {
const detections = await faceapi.detectAllFaces(video, new faceapi.TinyFaceDetectorOptions())
.withFaceLandmarks()
.withFaceExpressions()
.withAgeAndGender();
overlayContext.clearRect(0, 0, overlay.width, overlay.height);
const resizedDetections = faceapi.resizeResults(detections, displaySize);
resizedDetections.forEach(detection => {
const box = detection.detection.box;
const age = parseFloat(detection.age.toFixed(0));
const gender = detection.gender;
const expressions = detection.expressions;
const currentExpression = calculateCurrentExpression(expressions);
overlayContext.strokeStyle = 'red';
overlayContext.lineWidth = 2;
overlayContext.strokeRect(box.x, box.y, box.width, box.height);
overlayContext.font = '16px Arial';
overlayContext.fillStyle = 'yellow';
overlayContext.fillText(`感情: ${currentExpression}`, box.x, box.y - 20);
overlayContext.fillText(`年齢: ${age}`, box.x, box.y - 40);
overlayContext.fillText(`性別: ${gender}`, box.x, box.y - 60);
});
requestAnimationFrame(detectFaces);
}
}
detectFaces();
});
}
function calculateCurrentExpression(expressions) {
return Object.keys(expressions).reduce((a, b) => expressions[a] > expressions[b] ? a : b);
}
</script>
</body>
</html>
※下記サイトより全ソースのzipファイルをダウンロード後、weightsフォルダの中身を、index.htmlが配置されているフォルダにmodelsフォルダを作成し、そこに配置してください。
物体認識(TensorFlow.js)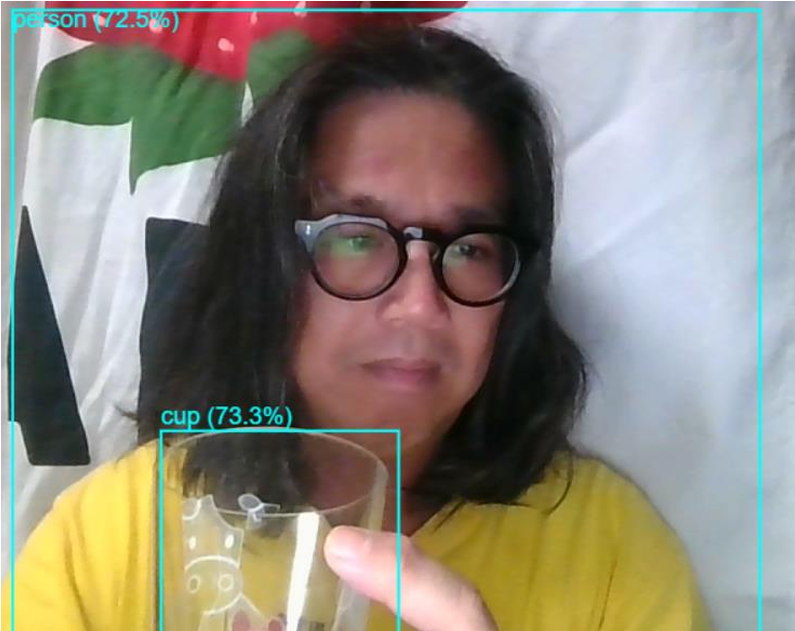
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>物体検出サンプルプログラム</title>
<style>
body, html { margin: 0; padding: 0; }
video, canvas {
position: absolute;
top: 0;
left: 0;
}
#videoElement {
z-index: 1;
}
#canvasElement {
z-index: 2;
}
</style>
<!-- TensorFlow.jsライブラリ -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@3.21.0/dist/tf.min.js"></script>
<!-- COCO-SSDモデル -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/coco-ssd@2.2.2"></script>
</head>
<body>
<video id="videoElement" width="640" height="480" autoplay muted></video>
<canvas id="canvasElement" width="640" height="480"></canvas>
<script>
const video = document.getElementById('videoElement');
const canvas = document.getElementById('canvasElement');
const ctx = canvas.getContext('2d');
// カメラ映像を取得
navigator.mediaDevices.getUserMedia({ video: true })
.then(stream => {
video.srcObject = stream;
video.play();
})
.catch(err => {
console.error('カメラへのアクセスが拒否されました:', err);
});
// モデルをロードして推論を開始
let model;
cocoSsd.load().then(loadedModel => {
model = loadedModel;
requestAnimationFrame(detectFrame);
});
function detectFrame() {
model.detect(video).then(predictions => {
drawPredictions(predictions);
requestAnimationFrame(detectFrame);
});
}
function drawPredictions(predictions) {
ctx.clearRect(0, 0, canvas.width, canvas.height);
ctx.drawImage(video, 0, 0, canvas.width, canvas.height);
predictions.forEach(prediction => {
// バウンディングボックスを描画
ctx.strokeStyle = '#00FFFF';
ctx.lineWidth = 2;
ctx.strokeRect(...prediction.bbox);
// ラベルとスコアを描画
ctx.font = '18px Arial';
ctx.fillStyle = '#00FFFF';
ctx.fillText(
`${prediction.class} (${(prediction.score * 100).toFixed(1)}%)`,
prediction.bbox[0],
prediction.bbox[1] > 20 ? prediction.bbox[1] - 5 : 20
);
});
}
</script>
</body>
</html>

<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>姿勢検出サンプル</title>
<style>
body { margin: 0; }
canvas {
position: absolute;
left: 0;
top: 0;
}
video {
display: none;
}
</style>
<!-- TensorFlow.js ライブラリ -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@3.18.0/dist/tf.min.js"></script>
<!-- PoseNetモデル -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/posenet@2.2.2/dist/posenet.min.js"></script>
</head>
<body>
<video id="video" width="640" height="480" autoplay playsinline></video>
<canvas id="canvas" width="640" height="480"></canvas>
<script>
async function setupCamera() {
const video = document.getElementById('video');
const stream = await navigator.mediaDevices.getUserMedia({
'audio': false,
'video': { facingMode: 'user' },
});
video.srcObject = stream;
return new Promise((resolve) => {
video.onloadedmetadata = () => {
resolve(video);
};
});
}
function drawKeypoints(keypoints, minConfidence, ctx, scale = 1) {
for (let i = 0; i < keypoints.length; i++) {
const keypoint = keypoints[i];
if (keypoint.score < minConfidence) continue;
const { y, x } = keypoint.position;
ctx.beginPath();
ctx.arc(x * scale, y * scale, 5, 0, 2 * Math.PI);
ctx.fillStyle = 'aqua';
ctx.fill();
}
}
function drawSkeleton(keypoints, minConfidence, ctx, scale = 1) {
const adjacentKeyPoints = posenet.getAdjacentKeyPoints(keypoints, minConfidence);
adjacentKeyPoints.forEach((keypoints) => {
drawSegment(
[keypoints[0].position.x, keypoints[0].position.y],
[keypoints[1].position.x, keypoints[1].position.y],
ctx, scale
);
});
}
function drawSegment([ax, ay], [bx, by], ctx, scale = 1) {
ctx.beginPath();
ctx.moveTo(ax * scale, ay * scale);
ctx.lineTo(bx * scale, by * scale);
ctx.lineWidth = 2;
ctx.strokeStyle = 'lime';
ctx.stroke();
}
async function main() {
const net = await posenet.load();
const video = await setupCamera();
video.play();
const canvas = document.getElementById('canvas');
const ctx = canvas.getContext('2d');
canvas.width = video.videoWidth;
canvas.height = video.videoHeight;
async function poseDetectionFrame() {
const pose = await net.estimateSinglePose(video, {
flipHorizontal: true
});
ctx.clearRect(0, 0, canvas.width, canvas.height);
ctx.save();
ctx.scale(-1, 1);
ctx.translate(-canvas.width, 0);
ctx.drawImage(video, 0, 0, canvas.width, canvas.height);
ctx.restore();
drawKeypoints(pose.keypoints, 0.5, ctx);
drawSkeleton(pose.keypoints, 0.5, ctx);
requestAnimationFrame(poseDetectionFrame);
}
poseDetectionFrame();
}
main();
</script>
</body>
</html>

<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>リアルタイムセグメンテーション</title>
<!-- TensorFlow.js と BodyPix ライブラリの読み込み -->
<script src="https://cdn.jsdelivr.net/npm/@tensorflow/tfjs@3.13.0"></script>
<script src="https://cdn.jsdelivr.net/npm/@tensorflow-models/body-pix@2.0.5"></script>
<style>
/* ビデオとキャンバスの重ね合わせ */
#canvas {
position: absolute;
top: 0;
left: 0;
z-index: 1;
}
#video {
position: absolute;
top: 0;
left: 0;
z-index: 0;
}
</style>
</head>
<body>
<video id="video" autoplay playsinline muted></video>
<canvas id="canvas"></canvas>
<script>
const videoElement = document.getElementById('video');
const canvasElement = document.getElementById('canvas');
const ctx = canvasElement.getContext('2d');
// カメラの映像を取得する関数
async function setupCamera() {
const stream = await navigator.mediaDevices.getUserMedia({
video: { width: 640, height: 480 }
});
videoElement.srcObject = stream;
return new Promise((resolve) => {
videoElement.onloadedmetadata = () => {
// サイズを指定
videoElement.width = videoElement.videoWidth;
videoElement.height = videoElement.videoHeight;
canvasElement.width = videoElement.videoWidth;
canvasElement.height = videoElement.videoHeight;
resolve();
};
});
}
// BodyPixモデルの読み込み
async function loadBodyPix() {
return await bodyPix.load();
}
// 映像フレームをセグメントする関数
async function segmentFrame(model) {
if (videoElement.readyState < 2) { // 映像の準備ができていない場合
requestAnimationFrame(() => segmentFrame(model));
return;
}
// セグメンテーションの実行
const segmentation = await model.segmentPerson(videoElement, {
internalResolution: 'medium',
segmentationThreshold: 0.7
});
// 背景を白く塗りつぶし
ctx.fillStyle = "white";
ctx.fillRect(0, 0, canvasElement.width, canvasElement.height);
// マスクを適用して人物のみ表示
const mask = bodyPix.toMask(segmentation);
const opacity = 1.0; // マスクの不透明度を100%にする
const maskBlurAmount = 0;
const flipHorizontal = false;
// マスクをキャンバスに描画
bodyPix.drawMask(
canvasElement, videoElement, mask,
opacity, maskBlurAmount, flipHorizontal
);
// 次のフレームをリクエスト
requestAnimationFrame(() => segmentFrame(model));
}
// メイン処理
async function main() {
await setupCamera(); // カメラの初期化
const model = await loadBodyPix(); // BodyPixモデルの読み込み
// セグメンテーションを開始
segmentFrame(model);
}
main(); // メイン処理の実行
</script>
</body>
</html>
動きましたか?
このレベルのものがブラウザのみで動作するというのは非常に良い時代になったものです!
📹 TensorFlow.jsというライブラリについて 🙋
TensorFlow.jsというライブラリを利用すると、JavaScriptのみで画像処理などの多くのAIのモデルを動かすことが出来ます。このライブラリとChatGPT APIなどのマルチモーダルなLLMとプログラミングを組み合わせると、いままで考えられなかった面白いことが行えるような予感がしますよね!
【TensorFlow.js】
下記のように、即時動かして試すことも可能です。
【顔認識のデモ】
【手を認識するデモ】
📹 ChatGPT APIとの連携 🙋
Webアプリケーションで画像を扱う場合、セキュリティ面を考えると、バックエンド=WEBアプリケーションサーバーが必要となってきます。
このバックエンドの環境構築は非常に難しそうに感じますが…非常に簡単に構築することができますので、下記の記事を参考にflaskの簡易アプリケーションサーバーを構築してみて下さい。
Windows環境であればOpenAI のAPIキーとOpenAI へのアクセスが出来れば全て自分のPC内で動作させることが出来ます!
※サンプルはあくまでローカル環境で動かすのみで、外部公開を考慮していません。インターネットサービスとしては公開しないでください!
「顔が中央に来たら1回だけ好きそうな食べ物・趣味を想像表示」するアプリです。ChatGPTさんの独断と偏見で語られますので、全然本当ではない結果となりますが、それが逆に面白いという感じですね!!
【ソースファイル】※バックエンドは一切変更なし
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>好きな食べ物や趣味趣向を想像して表示</title>
<style>
body {
display: flex;
flex-direction: column;
align-items: center;
justify-content: flex-start;
margin: 0;
padding: 20px;
}
video, canvas {
border: 1px solid black;
margin: 10px;
}
#video {
position: relative;
}
#overlay {
position: absolute;
top: 0;
left: 0;
}
.canvas-container {
position: relative;
width: 720px;
height: 560px;
}
#resultArea {
width: 720px;
min-height: 120px;
border: 1px solid #ccc;
padding: 10px;
margin-top: 10px;
}
#reloadBtn {
margin-top: 10px;
}
</style>
</head>
<body>
<h1>顔が中央に来たら1回だけ好きそうな食べ物・趣味を想像表示</h1>
<!-- ビデオとオーバーレイキャンバス -->
<div class="canvas-container">
<video id="video" width="720" height="560" autoplay muted></video>
<canvas id="overlay" width="720" height="560"></canvas>
</div>
<!-- 結果表示用エリア -->
<div id="resultArea">ここに想像結果が表示されます...</div>
<button id="reloadBtn">リセットして再度試す</button>
<!-- face-api.jsのUMD -->
<script src="https://unpkg.com/face-api.js@0.22.2/dist/face-api.min.js"></script>
<script>
// ======== 定数・変数定義 ========
const video = document.getElementById('video');
const overlay = document.getElementById('overlay');
const overlayCtx = overlay.getContext('2d');
const displaySize = { width: video.width, height: video.height };
// 顔が中央かどうかの判定用パラメータ
const CENTER_THRESHOLD_X = 100; // x方向(左右)のゆとり
const CENTER_THRESHOLD_Y = 100; // y方向(上下)のゆとり
const FACE_SIZE_THRESHOLD = 200; // 顔の幅がこのpx以上なら「十分大きい」
// すでにAPIを呼び出したかを管理するフラグ (trueなら2回目以降呼び出ししない)
let isApiCalled = false;
// ======== カメラ映像を取得 ========
navigator.mediaDevices.getUserMedia({ video: {} })
.then(stream => { video.srcObject = stream; })
.catch(err => { console.error("カメラへのアクセスに失敗:", err); });
// ======== モデル読み込み ========
Promise.all([
faceapi.nets.tinyFaceDetector.loadFromUri('models'),
faceapi.nets.faceLandmark68Net.loadFromUri('models'),
faceapi.nets.faceExpressionNet.loadFromUri('models'),
faceapi.nets.ageGenderNet.loadFromUri('models')
]).then(startFaceDetection)
.catch(err => console.error("モデルのロードに失敗:", err));
// ======== 顔認識を開始する関数 ========
function startFaceDetection() {
video.addEventListener('play', async () => {
faceapi.matchDimensions(overlay, displaySize);
// カメラ映像が再生されている間、常に検出
const detectionLoop = async () => {
if (video.paused || video.ended) {
return;
}
// 顔検出(withFaceLandmarks など組み合わせ可)
const detections = await faceapi.detectAllFaces(
video,
new faceapi.TinyFaceDetectorOptions()
).withFaceLandmarks().withFaceExpressions().withAgeAndGender();
// 描画をクリア
overlayCtx.clearRect(0, 0, overlay.width, overlay.height);
// 検出結果をリサイズ
const resized = faceapi.resizeResults(detections, displaySize);
// 各検出された顔について処理
resized.forEach(det => {
const box = det.detection.box;
overlayCtx.strokeStyle = 'red';
overlayCtx.lineWidth = 2;
// 顔枠を描画
overlayCtx.strokeRect(box.x, box.y, box.width, box.height);
// 情報文字列を描画
overlayCtx.font = '16px sans-serif';
overlayCtx.fillStyle = 'yellow';
const age = det.age?.toFixed(0) || '??';
const gender = det.gender || '??';
const expressions = det.expressions;
const maxExp = Object.keys(expressions).reduce((prev, curr) => {
return expressions[prev] > expressions[curr] ? prev : curr;
});
overlayCtx.fillText(`年齢:${age} 性別:${gender} 表情:${maxExp}`, box.x, box.y - 10);
// ======== 顔が中央か判定 ========
// 顔の中心
const faceCenterX = box.x + box.width / 2;
const faceCenterY = box.y + box.height / 2;
// 動画キャンバスの中央
const centerX = displaySize.width / 2;
const centerY = displaySize.height / 2;
// 「中心付近&顔サイズ大きい」なら true
const isNearCenter = (
Math.abs(faceCenterX - centerX) < CENTER_THRESHOLD_X &&
Math.abs(faceCenterY - centerY) < CENTER_THRESHOLD_Y
);
const isLargeFace = (box.width >= FACE_SIZE_THRESHOLD);
if (isNearCenter && isLargeFace && !isApiCalled) {
// まだAPIを呼んでいなければ、ここで1回だけ呼ぶ
isApiCalled = true;
callOpenAIApi(age, gender, maxExp);
}
});
requestAnimationFrame(detectionLoop);
};
detectionLoop();
});
}
// ======== /api/chat を呼ぶ関数 ========
async function callOpenAIApi(age, gender, expression) {
const resultDiv = document.getElementById('resultArea');
resultDiv.textContent = "想像中... しばらくお待ちください。";
try {
// ChatGPTに投げるメッセージを作成(本当に好きな食べ物や趣味を想像してもらうだけ)
const userContent = `
あなたは優秀な人相学者です。以下の条件の人物の「好きそうな食べ物・趣味趣向」について、
あくまで想像でかまいませんので、できるだけ具体的に教えてください。なるべく極端に決めつけるようで面白おかしく興味深い特徴を示してください。
- おおよその年齢: ${age}歳
- 性別: ${gender}
- 今の表情: ${expression}
回答は日本語で、敬体(です・ます調)でお願いします。
`;
const requestBody = {
model: "gpt-4o",
messages: [
{ role: "system", content: "あなたは非常に優秀なカウンセラー兼人相学の専門家です。" },
{ role: "user", content: userContent }
],
temperature: 0.7,
max_tokens: 1000
};
// フロントエンド2のように endpoint を "http://localhost/api" に合わせてもOK
const chatApiUrl = "http://localhost/api/chat";
const response = await fetch(chatApiUrl, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify(requestBody)
});
if (!response.ok) {
const errText = await response.text();
throw new Error(`APIエラー: ${errText}`);
}
const data = await response.json();
// OpenAIのレスポンス(アシスタントメッセージ)を取得
const assistantMsg = data.choices?.[0]?.message?.content;
if (assistantMsg) {
// 結果を表示
resultDiv.innerHTML = `<strong>想像結果:</strong><br>${assistantMsg.replace(/\n/g, "<br>")}`;
} else {
resultDiv.textContent = "AIの応答が空でした。";
}
} catch (err) {
console.error(err);
document.getElementById('resultArea').textContent = "エラーが発生しました。" + err.message;
}
}
// ======== リセットボタン処理 ========
document.getElementById('reloadBtn').addEventListener('click', () => {
isApiCalled = false;
document.getElementById('resultArea').textContent = "ここに想像結果が表示されます...";
});
</script>
</body>
</html>

ぼ…盆栽!?
間違った認識ですが、AIが可愛いくて毒舌な女の子キャラ設定で
「キミって盆栽好きそうだよね!」
なんて言われたら
「えぇ!?なんでそう思うの!!」
とか言い返してしまい、コミュニケーションをとっているうちに、自分の好みとかの情報を全て吸い取られそうですw
…それは冗談として、このあたりの精度をまともにするのであれば、心理学や人相学の勉強をして、RAGを利用したりなどプロンプトとプログラム部分をもっと頑張って構築する必要がありそうですね!!
最後に、ここに掲載したフロントエンド側のプログラムを置いておきます。
(CDLEコミュニティメンバーのみダウンロード可能です)
バックエンド側のプログラムは「3分AIプログラミング」の記事から取ってきてください!